
A mesterséges intelligencia elősegíti az emberhez hasonló interakciókat a számítástechnikai rendszerekkel, míg a gépi tanulás lehetővé teszi, hogy ezek a gépek megtanulják utánozni az emberi intelligenciát minden interakció során. De miben rejlik ezek a rendkívül fejlett ML és AI eszközök? Adatok megjegyzése.
Az adatok az ML algoritmusok nyersanyaga – minél több adatot alkalmaz, annál jobb lesz az AI-termék. Noha kritikus fontosságú a nagy mennyiségű adathoz való hozzáférés, ugyanilyen fontos gondoskodni arról, hogy azok pontos megjegyzésekkel legyenek ellátva a megvalósítható eredmények elérése érdekében. Az adatfeljegyzések a fejlett, megbízható és pontos ML algoritmikus teljesítmény mögött álló adaterőmű.
Az adatannotáció szerepe az AI képzésben
Az adatok annotáció kulcsszerepet játszik az ML képzésben és az AI projektek általános sikerében. Segít azonosítani a konkrét képeket, adatokat, célokat és videókat, és felcímkézi őket, hogy a gép könnyebben azonosítsa a mintákat és osztályozza az adatokat. Ez egy ember által vezetett feladat, amely megtanítja az ML-modellt a pontos előrejelzésekre.
Ha az adatjelölést nem hajtják végre pontosan, az ML algoritmus nem tudja könnyen társítani az attribútumokat objektumokhoz.
A megjegyzésekkel ellátott képzési adatok jelentősége az AI-rendszereknél
Az adatannotáció lehetővé teszi az ML modellek pontos működését. Vitathatatlan kapcsolat van az adatfeljegyzések pontossága és pontossága, valamint az AI-projekt sikere között.
A 119-ben 2022 milliárd dollárra becsült globális mesterséges intelligencia piaci értéke az előrejelzések szerint eléri $ 1,597 milliárd 203038%-os CAGR-rel nőtt az időszak során. Míg a teljes mesterségesintelligencia-projekt több kritikus lépésen megy keresztül, az adatjelölési szakaszban van a projekt a legjelentősebb szakaszban.
Az adatok gyűjtése az adatok kedvéért nem sokat segít a projektben. Hatalmas mennyiségű kiváló minőségű, releváns adatra van szüksége AI-projektjének sikeres megvalósításához. Az ML projektek fejlesztésében eltöltött idejének körülbelül 80%-át az adatokkal kapcsolatos feladatokra fordítják, mint például a címkézés, súrolás, összesítés, azonosítás, kiegészítés és annotálás.
Az adatok megjegyzése az egyik olyan terület, ahol az emberek előnyben vannak a számítógépekkel szemben, mivel velünk született képességünk van a szándékok megfejtésére, a kétértelműségek átgázolására és a bizonytalan információk osztályozására.
Miért fontos az adatjelölés?
A mesterséges intelligencia megoldásának értéke és hitelessége nagymértékben függ a modellképzéshez használt adatbevitel minőségétől.
Egy gép nem tudja úgy feldolgozni a képeket, mint mi; meg kell őket képezni a minták felismerésére a tréningen keresztül. Mivel a gépi tanulási modellek az alkalmazások széles skáláját szolgálják – olyan kritikus megoldásokat, mint az egészségügyi ellátás és az autonóm járművek –, ahol az adatfeljegyzések hibáinak veszélyes következményei lehetnek.
Az adatjelölés biztosítja, hogy mesterséges intelligencia megoldása teljes mértékben működjön. Az ML-modell betanítása, hogy pontosan értelmezze környezetét mintákon és összefüggéseken keresztül, előrejelzéseket készítsen és megtegye a szükséges lépéseket, erősen kategorizált és megjegyzésekkel ellátott. képzési adatok. A megjegyzés megmutatja az ML-modellnek a szükséges előrejelzést az adatkészlet kritikus jellemzőinek címkézésével, átírásával és címkézésével.
Felügyelt tanulás
Mielőtt mélyebben beleásnánk az adatfeljegyzésekbe, fejtsük ki az adatannotációt felügyelt és felügyelet nélküli tanulással.
A gépi tanulás által felügyelt gépi tanulás egy alkategóriája jól címkézett adatkészlet segítségével jelzi az AI-modell betanítását. A felügyelt tanulási módszerben bizonyos adatok már pontosan meg vannak jelölve és megjegyzésekkel ellátva. Az ML-modell, amikor új adatoknak van kitéve, a betanítási adatokat használja fel, hogy pontos előrejelzést adjon a címkézett adatok alapján.
Például az ML modellt egy különböző típusú ruhákkal teli szekrényen képezik ki. A képzés első lépése az lenne, hogy a modellt különböző típusú ruhákkal képezzék ki, felhasználva az egyes ruhadarabok jellemzőit és tulajdonságait. A betanítás után a gép korábbi ismereteinek vagy képzettségének alkalmazásával képes lesz azonosítani a különálló ruhadarabokat. A felügyelt tanulás osztályozásra (kategória alapján) és regresszióra (valós érték alapján) sorolható.
Hogyan befolyásolja az adatannotáció az AI-rendszerek teljesítményét
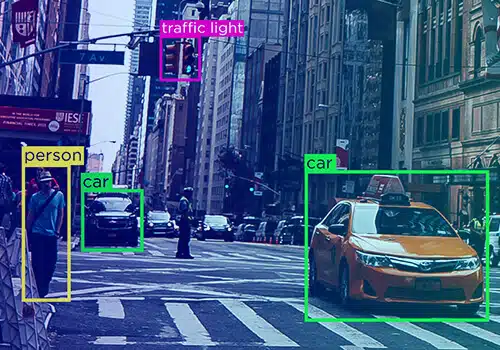 Az adatok soha nem egyetlen entitás – különböző formákat öltenek – szöveg, videó és kép. Mondanunk sem kell, hogy az adatjelölések különböző formákban léteznek.
Az adatok soha nem egyetlen entitás – különböző formákat öltenek – szöveg, videó és kép. Mondanunk sem kell, hogy az adatjelölések különböző formákban léteznek.
Ahhoz, hogy a gép megértse és pontosan azonosítsa a különböző entitásokat, fontos hangsúlyozni a Named Entity Tagging minőségét. Egy hiba a címkézésben és a megjegyzésekben, és az ML nem tudott különbséget tenni Amazon között – az e-kereskedelmi üzlet, a folyó vagy a papagáj között.
Emellett az adatok megjegyzései segítik a gépeket a finom szándékok felismerésében – ez a tulajdonság az emberben magától értetődő. Különböző módon kommunikálunk, és az emberek megértik a kifejezetten kifejezett gondolatokat és a hallgatólagos üzeneteket is. Például a közösségi média válaszai vagy véleményei lehetnek pozitívak és negatívak is, és az ML-nek meg kell tudnia érteni mindkettőt. 'Nagyszerű hely. Újra meglátogatom. Ez egy pozitív kifejezés, miközben „milyen nagyszerű hely volt régen! Szerettük ezt a helyet! negatív, és az emberi megjegyzések sokkal könnyebbé tehetik ezt a folyamatot.

Az adatfeljegyzésekkel kapcsolatos kihívások és azok leküzdése
Az adatfeljegyzések két fő kihívása a költség és a pontosság.
Nagyon pontos adatok szükségessége: Az AI és ML projektek sorsa a megjegyzésekkel ellátott adatok minőségétől függ. Az ML és AI modelleket következetesen jól osztályozott adatokkal kell táplálni, amelyek képesek a modellt arra tanítani, hogy felismerje a változók közötti korrelációt.
Nagy mennyiségű adatra van szükség: Minden ML és AI modell jól működik a nagy adatkészleteken – egyetlen ML projekthez legalább több ezer címkézett elemre van szükség.
Az erőforrások szükségessége: Az AI-projektek erőforrás-függőek, mind a költségek, mind az idő, mind a munkaerő tekintetében. Ezek egyike nélkül az adatfeliratozási projekt minősége tönkremehet.
[Olvassa el még: Videó megjegyzés a gépi tanuláshoz ]
Az adatjelölések bevált gyakorlatai
Az adatok megjegyzéseinek értéke nyilvánvaló az AI-projekt kimenetelére gyakorolt hatásában. Ha az adatkészlet, amelyen az ML modelljeit tanítja, tele van inkonzisztenciákkal, torzított, kiegyensúlyozatlan vagy sérült, akkor az AI-megoldás meghibásodhat. Ezen túlmenően, ha a címkék rosszak, és a megjegyzések nem következetesek, akkor az AI-megoldás is pontatlan előrejelzéseket eredményez. Tehát mik a legjobb gyakorlatok az adatjelölések terén?
Tippek a hatékony és eredményes adatjelöléshez
- Győződjön meg arról, hogy a létrehozott adatcímkék specifikusak és összhangban vannak a projekt igényeivel, ugyanakkor elég általánosak ahhoz, hogy az összes lehetséges változatot kielégítsék.
- Jegyezze fel a gépi tanulási modell betanításához szükséges nagy mennyiségű adatot. Minél több adatot ír fel, annál jobb lesz a modellképzés eredménye.
- Az adatfeljegyzésekre vonatkozó irányelvek nagymértékben hozzájárulnak a minőségi szabványok megállapításához és a konzisztencia biztosításához a projekt egészében és több annotátor között.
- Mivel az adatfeljegyzések költségesek és munkaerő-függőek lehetnek, ésszerű a szolgáltatóktól származó előre felcímkézett adatkészletek ellenőrzése.
- A pontos adatfeljegyzések és oktatás elősegítése érdekében használja a humán hurok hatékonyságát a sokszínűség és a kritikus esetek kezeléséhez, valamint az annotációs szoftver képességeihez.
- A minőséget előnyben részesítse az annotátorok minőségi megfelelőségének, pontosságának és konzisztenciájának tesztelésével.
A minőség-ellenőrzés jelentősége az annotációs folyamatban
 A minőségi adatjelölés a nagy teljesítményű AI-megoldások éltető eleme. A jól feljegyzett adatkészletek segítik az AI-rendszereket, hogy kifogástalanul jól teljesítsenek, még kaotikus környezetben is. Hasonlóképpen, a fordítottja is ugyanúgy igaz. Az annotációs pontatlanságokkal teli adatkészlet inkonzisztens megoldásokat fog felmutatni.
A minőségi adatjelölés a nagy teljesítményű AI-megoldások éltető eleme. A jól feljegyzett adatkészletek segítik az AI-rendszereket, hogy kifogástalanul jól teljesítsenek, még kaotikus környezetben is. Hasonlóképpen, a fordítottja is ugyanúgy igaz. Az annotációs pontatlanságokkal teli adatkészlet inkonzisztens megoldásokat fog felmutatni.
Tehát a képminőség-ellenőrzés, a videócímkézés és a megjegyzések folyamata jelentős szerepet játszik az AI kimenetelében. Mindazonáltal a magas színvonalú ellenőrzési szabványok fenntartása az annotációs folyamat során kihívást jelent a kis- és nagyvállalatok számára. A különféle típusú annotációs eszközöktől és a sokféle annotációs munkaerőtől való függést nehéz lehet felmérni és fenntartani a minőségi konzisztenciát.
Az elosztott vagy távoli munkaadat-annotátorok minőségének fenntartása nehéz feladat, különösen azok számára, akik nem ismerik a szükséges szabványokat. Ezenkívül a hibaelhárítás vagy a hibajavítás időbe telhet, mivel azt egy megosztott munkaerőn belül azonosítani kell.
A megoldás az lenne, ha betanítanák az annotátorokat, egy felügyelőt bevonnának, vagy ha több adatjegyző megvizsgálná és felülvizsgálná az adatkészlet-annotáció pontosságát. Végül rendszeresen teszteljük az annotátorokat a szabványok ismeretében.
Az annotátorok szerepe és az adatokhoz megfelelő annotátorok kiválasztása
Az emberi annotátorok tartják a kulcsot egy sikeres AI-projekthez. Az adatjegyzők biztosítják az adatok pontos, következetes és megbízható megjegyzéseit, mivel kontextust biztosíthatnak, megérthetik a szándékot, és megalapozhatják az adatok igazságtartalmát.
Egyes adatok mesterségesen vagy automatikusan annotálásra kerülnek automatizálási megoldások segítségével, megfelelő fokú megbízhatósággal. Például letölthet több százezer képet a házakról a Google-ról, és adatkészletként készítheti el őket. Az adatkészlet pontossága azonban csak akkor határozható meg megbízhatóan, ha a modell megkezdte a teljesítményét.
Az automatizált automatizálás megkönnyítheti és gyorsabbá teheti a dolgokat, de tagadhatatlanul kevésbé pontos. A másik oldalon az emberi annotátor lassabb és költségesebb lehet, de pontosabb.
Az emberi adatok annotátorok megjegyzéseket fűzhetnek és osztályozhatják az adatokat tárgyi szakértelmük, veleszületett tudásuk és speciális képzettségük alapján. Az adatjegyzők pontosságot, pontosságot és következetességet biztosítanak.
[Olvassa el még: Útmutató kezdőknek az adatjelölésekhez: tippek és bevált módszerek ]
Következtetés
Nagy teljesítményű AI-projekt létrehozásához jó minőségű, megjegyzésekkel ellátott képzési adatokra van szükség. Míg a jól jelzett adatok következetes beszerzése idő- és erőforrás-igényes lehet – még a nagyvállalatok számára is – a megoldás az olyan bejáratott adatfeljegyzési szolgáltatók, mint a Shaip szolgáltatásainak igénybevétele. A Shaipnél adatfeljegyzésekre szakosodott szolgáltatásainkon keresztül segítünk az AI-képességek bővítésében a piaci és vásárlói igények kielégítésére.


