
Bevezetés
Ez az útmutató rendkívül hasznos lesz azoknak a vásárlóknak és döntéshozóknak, akik az ideghálózatok, valamint az egyéb AI és ML műveletek esetében kezdik el gondolataikat az adatszerzés és az adatok megvalósításának csavarjai felé fordítani.

Ez a cikk teljes mértékben annak szentelt, hogy megvilágítsa, mi a folyamat, miért elkerülhetetlen, döntő
tényezőket, amelyeket a vállalatoknak figyelembe kell venniük, amikor az adat -feliratozási eszközökhöz fordulnak, és így tovább. Tehát, ha vállalkozása van, készüljön felvilágosításra, mivel ez az útmutató végigvezet mindent, amit az adatjegyzésekről tudni kell.
Lássunk neki.
Azok számára, akik végigolvasták a cikket, íme néhány gyors elvétel, amelyeket az útmutatóban talál:
- Értse meg, mi az adat annotáció
- Ismerje az adat annotációs folyamatok különféle típusait
- Ismerje meg az adatfelismerési folyamat megvalósításának előnyeit
- Tisztázza, hogy érdemes-e házon belüli adatcímkézésre, vagy kiszervezésre
- Betekintés a megfelelő adatjegyzetek kiválasztására is
Mi a gépi tanulás?
 Beszéltünk arról, hogy az adatok megjegyzése vagy adatcímkézés támogatja a gépi tanulást, és az összetevők címkézéséből vagy azonosításából áll. De ami a mély tanulást és magát a gépi tanulást illeti: a gépi tanulás alapfeltevése az, hogy a számítógépes rendszerek és programok az emberi kognitív folyamatokhoz hasonló módon, közvetlen emberi segítség vagy beavatkozás nélkül javíthatják a kimenetüket, hogy betekintést nyerjünk. Más szóval önképző gépekké válnak, amelyek-akárcsak az ember-jobb gyakorlattal válnak munkájukhoz. Ez a „gyakorlat” több (és jobb) képzési adat elemzéséből és értelmezéséből származik.
Beszéltünk arról, hogy az adatok megjegyzése vagy adatcímkézés támogatja a gépi tanulást, és az összetevők címkézéséből vagy azonosításából áll. De ami a mély tanulást és magát a gépi tanulást illeti: a gépi tanulás alapfeltevése az, hogy a számítógépes rendszerek és programok az emberi kognitív folyamatokhoz hasonló módon, közvetlen emberi segítség vagy beavatkozás nélkül javíthatják a kimenetüket, hogy betekintést nyerjünk. Más szóval önképző gépekké válnak, amelyek-akárcsak az ember-jobb gyakorlattal válnak munkájukhoz. Ez a „gyakorlat” több (és jobb) képzési adat elemzéséből és értelmezéséből származik.
Mi az adatmegjegyzés?
Az adatjelölés az adatok hozzárendelésének, címkézésének vagy címkézésének folyamata, amely segít a gépi tanulási algoritmusoknak megérteni és osztályozni az általuk feldolgozott információkat. Ez a folyamat elengedhetetlen az AI-modellek betanításához, lehetővé téve számukra, hogy pontosan megértsék a különféle adattípusokat, például képeket, hangfájlokat, videofelvételeket vagy szöveget.
Képzeljen el egy önvezető autót, amely számítógépes látásból, természetes nyelvi feldolgozásból (NLP) és érzékelőkből származó adatokra támaszkodik a pontos vezetési döntések meghozatalához. Annak érdekében, hogy az autó mesterséges intelligencia modellje megkülönböztethesse az akadályokat, például más járműveket, gyalogosokat, állatokat vagy útlezárásokat, a kapott adatokat címkézni vagy megjegyzésekkel kell ellátni.
A felügyelt tanulás során az adatok megjegyzése különösen fontos, mivel minél több címkézett adatot táplálunk be a modellbe, annál gyorsabban tanul meg önállóan működni. A megjegyzésekkel ellátott adatok lehetővé teszik a mesterséges intelligencia modellek alkalmazását különféle alkalmazásokban, például chatbotokban, beszédfelismerésben és automatizálásban, ami optimális teljesítményt és megbízható eredményeket eredményez.
Mi az adatcímkézési/feliratozó eszköz?
 Egyszerűen fogalmazva, ez egy olyan platform vagy portál, amely lehetővé teszi a szakemberek és szakértők számára, hogy bármilyen típusú adatkészleteket megjegyzésekkel, címkékkel vagy címkékkel jelöljenek meg. Ez egy híd vagy közeg a nyers adatok és az eredmények között, amelyeket a gépi tanulási modulok végső soron kimerítenek.
Egyszerűen fogalmazva, ez egy olyan platform vagy portál, amely lehetővé teszi a szakemberek és szakértők számára, hogy bármilyen típusú adatkészleteket megjegyzésekkel, címkékkel vagy címkékkel jelöljenek meg. Ez egy híd vagy közeg a nyers adatok és az eredmények között, amelyeket a gépi tanulási modulok végső soron kimerítenek.
Az adatcímkéző eszköz egy közvetlen vagy felhőalapú megoldás, amely a gépi tanulási modellek kiváló minőségű képzési adatait jegyzi. Bár sok vállalat külső szolgáltatót bíz meg a bonyolult feliratozások elvégzésében, egyes szervezetek továbbra is rendelkeznek saját eszközökkel, amelyek vagy egyedi kialakításúak, vagy a piacon elérhető ingyenes vagy nyílt forráskódú eszközökön alapulnak. Az ilyen eszközöket általában bizonyos adattípusok kezelésére, például kép, videó, szöveg, hang stb. Csak kiválaszthatják az opciót, és elvégezhetik sajátos feladataikat.
Kép megjegyzés

Az általuk képzett adatkészletek alapján azonnal és pontosan meg tudják különböztetni a szemét az orrától, a szemöldökét a szempilláitól. Éppen ezért az alkalmazott szűrők tökéletesen illeszkednek, függetlenül az arc formájától, a fényképezőgéphez való közelségétől stb.
Szóval, mint most tudod, kép annotáció létfontosságú olyan modulokban, amelyek magukban foglalják az arcfelismerést, a számítógépes látást, a robotlátást és így tovább. Amikor az AI szakértői ilyen modelleket képeznek, feliratokat, azonosítókat és kulcsszavakat adnak hozzá képeikhez attribútumként. Az algoritmusok ezután azonosítják és megértik ezeket a paramétereket, és önállóan tanulnak.
Képosztályozás – A képosztályozás magában foglalja előre meghatározott kategóriák vagy címkék hozzárendelését a képekhez a tartalom alapján. Ezt a fajta megjegyzést arra használják, hogy az AI-modelleket megtanítsák a képek automatikus felismerésére és kategorizálására.
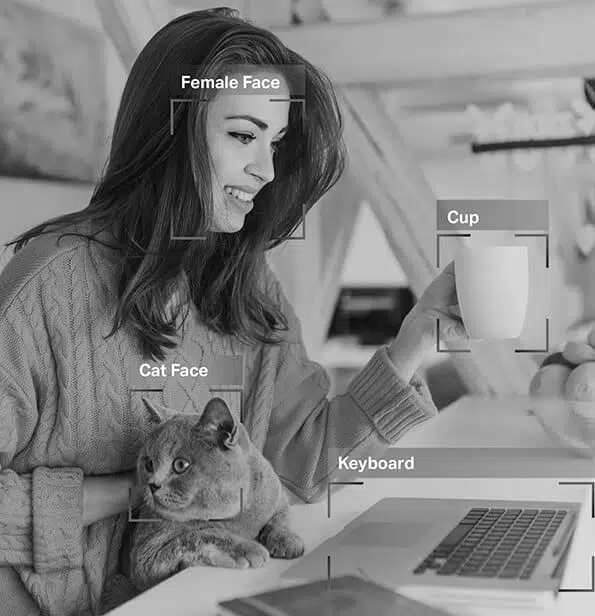
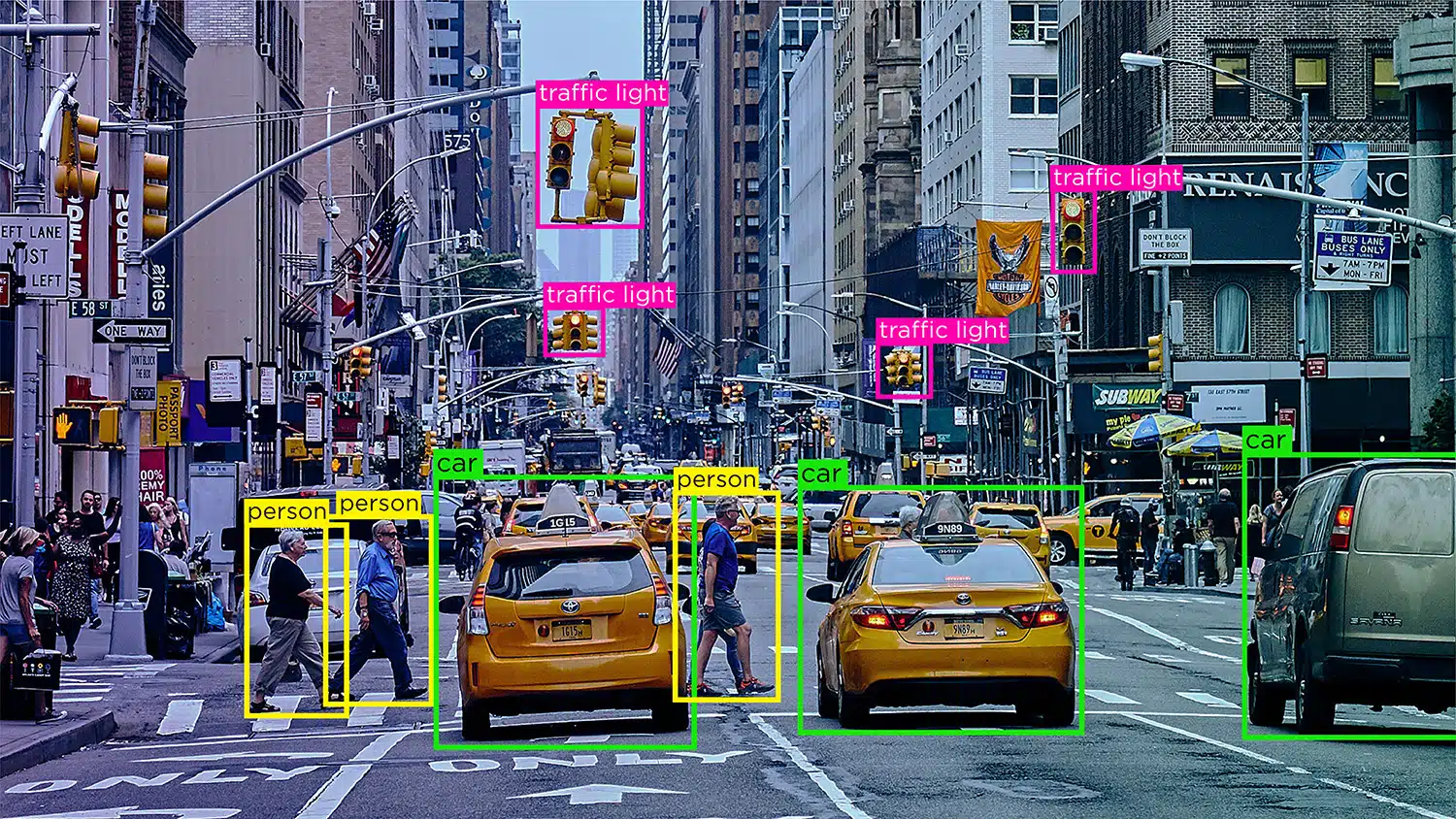
Tárgyfelismerés/-észlelés – Az objektumfelismerés vagy tárgyfelismerés a képen belüli meghatározott objektumok azonosításának és címkézésének folyamata. Ezt a fajta megjegyzést arra használják, hogy az AI-modelleket megtanítsák a valós képeken vagy videókon lévő objektumok lokalizálására és felismerésére.
szegmentálás – A képszegmentálás során egy képet több szegmensre vagy régióra osztanak fel, amelyek mindegyike egy adott objektumnak vagy érdeklődési területnek felel meg. Ezt a fajta megjegyzést arra használják, hogy az AI-modelleket pixelszintű képek elemzésére tanítsák, lehetővé téve a pontosabb objektumfelismerést és a jelenet megértését.
Hangjegyzet
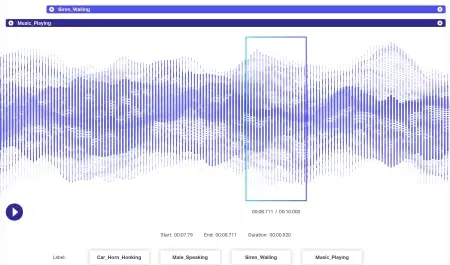
Az audio adatokhoz még több dinamika kapcsolódik, mint a képi adatokhoz. Számos tényező kapcsolódik egy audiofájlhoz, többek között, de határozottan nem kizárólag - nyelv, beszélő demográfia, nyelvjárások, hangulat, szándék, érzelem, viselkedés. Az algoritmusok hatékony feldolgozása érdekében ezeket a paramétereket azonosítani és címkézni kell olyan technikákkal, mint az időbélyegzés, a hangcímkézés és egyebek. A verbális jelzések mellett a nem verbális példákat, például a csendet, a lélegzetet, a háttérzajt is fel lehet jegyezni a rendszerek átfogó megértése érdekében.
Videó kommentárja

Amíg egy kép áll, a videó olyan képekből áll össze, amelyek a mozgásban lévő tárgyak hatását keltik. Most ennek az összeállításnak minden képét keretnek nevezzük. Ami a videó annotálását illeti, a folyamat kulcspontok, sokszögek vagy határoló dobozok hozzáadásával jár, hogy az egyes képkockákban a mező különböző objektumait feljegyezhesse.
Ha ezeket a kereteket összeillesztjük, a mozgást, a viselkedést, a mintákat és még sok mást megtanulhatnak az AI modellek működés közben. Csak keresztül videó kommentár hogy az olyan koncepciók, mint a lokalizáció, a mozgás elmosódása és az objektumkövetés megvalósíthatók rendszerekben.
Szövegjegyzet

Manapság a legtöbb vállalkozás a szöveges adatokra támaszkodik az egyedi betekintés és információ érdekében. A szöveg most bármi lehet, kezdve az alkalmazások visszajelzéseitől a közösségi médiák megemlítéséig. És a képekkel és videókkal ellentétben, amelyek többnyire egyenes előrejelzéseket közvetítenek, a szöveg sok szemantikával rendelkezik.
Emberként arra vagyunk ráhangolódva, hogy megértsük egy kifejezés összefüggéseit, minden szó, mondat vagy kifejezés jelentését, összefüggésbe hozzuk őket egy bizonyos helyzettel vagy beszélgetéssel, majd rájövünk egy állítás mögött rejlő holisztikus jelentésre. A gépek viszont ezt nem tudják pontosan megtenni. Az olyan fogalmak, mint a szarkazmus, a humor és más absztrakt elemek, ismeretlenek számukra, ezért megnehezíti a szöveges adatok címkézését. Ezért van a szöveges kommentároknak finomabb szakaszai, például a következők:
Szemantikus kommentár - az objektumokat, termékeket és szolgáltatásokat relevánsabbá teszik a megfelelő kulcsszavak címkézése és azonosítási paraméterei. A csevegőrobotokat úgy is készítik, hogy így utánozzák az emberi beszélgetéseket.
Szándékjegyzet - a felhasználók szándékát és az általuk használt nyelvet felcímkézik a gépek megértése érdekében. Ezzel a modellek megkülönböztethetik a kérést a parancstól, vagy az ajánlást a foglalástól stb.
Érzelmi annotáció – A hangulatjegyzetek közé tartozik a szöveges adatok címkézése az általuk közvetített hangulattal, például pozitív, negatív vagy semleges. Ezt a fajta annotációt általában a hangulatelemzésben használják, ahol a mesterséges intelligencia modelleket arra tanítják, hogy megértsék és értékeljék a szövegben kifejezett érzelmeket.

Entitás megjegyzés - ahol a strukturálatlan mondatokat felcímkézik, hogy azok értelmesebbé váljanak, és a gépek számára érthető formátumba kerüljenek. Ennek megvalósításához két szempont kapcsolódik - megnevezett entitás-felismerés és a entitás összekapcsolása. Az elnevezett entitásfelismerés az, amikor a helyek, emberek, események, szervezetek és egyebek nevét felcímkézik és azonosítják, az entitás összekapcsolása pedig az, amikor ezeket a címkéket az őket követő mondatokhoz, kifejezésekhez, tényekhez vagy véleményekhez kapcsolják. Ez a két folyamat együttesen hozza létre a kapcsolatot a társított szövegek és az azt körülvevő állítás között.
Szöveg kategorizálása – A mondatok vagy bekezdések címkézhetők és osztályozhatók átfogó témák, trendek, témák, vélemények, kategóriák (sport, szórakozás és hasonlók) és egyéb paraméterek alapján.
Az adatcímkézési és adatfeljegyzési folyamat legfontosabb lépései
Az adatjelölési folyamat egy sor jól meghatározott lépésből áll, amelyek biztosítják a gépi tanulási alkalmazások kiváló minőségű és pontos adatcímkézését. Ezek a lépések a folyamat minden aspektusára kiterjednek, az adatgyűjtéstől a megjegyzésekkel ellátott adatok további felhasználásra történő exportálásáig.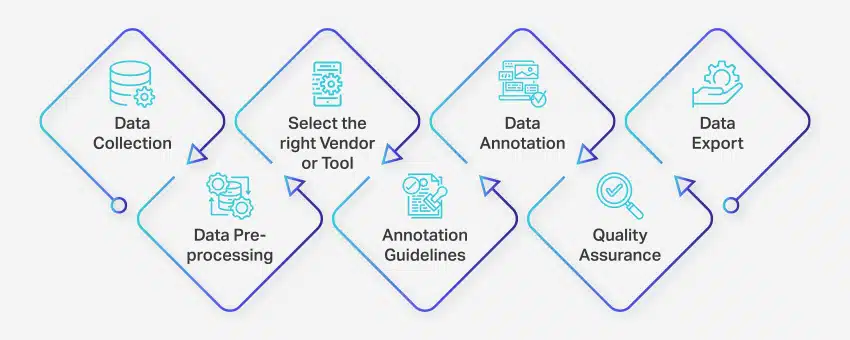
A következőképpen történik az adatfeljegyzés:
- Adatgyűjtés: Az adatannotálási folyamat első lépése az összes releváns adat, például képek, videók, hangfelvételek vagy szöveges adatok egy központi helyen történő összegyűjtése.
- Adatok előfeldolgozása: Szabványosítsa és javítsa az összegyűjtött adatokat a képek torzításának megszüntetésével, a szöveg formázásával vagy a videotartalom átírásával. Az előfeldolgozás biztosítja, hogy az adatok készen állnak a megjegyzésekre.
- Válassza ki a megfelelő szállítót vagy eszközt: Válassza ki a megfelelő adatfeljegyzési eszközt vagy szállítót a projekt követelményei alapján. A lehetőségek között szerepelnek olyan platformok, mint a Nanonets az adatok kommentálásához, a V7 a képannotációhoz, az Appen a videó megjegyzésekhez és a Nanonets a dokumentumok megjegyzéséhez.
- Annotációs irányelvek: Határozzon meg egyértelmű iránymutatásokat az annotátorok vagy annotációs eszközök számára, hogy biztosítsa a konzisztenciát és a pontosságot a folyamat során.
- Jegyzet: Az adatok címkézése és címkézése emberi annotátorok vagy adatfeliratozó szoftverek segítségével a megállapított irányelveket követve.
- Minőségbiztosítás (QA): Tekintse át a megjegyzésekkel ellátott adatokat a pontosság és a következetesség biztosítása érdekében. Ha szükséges, használjon több vak annotációt, hogy ellenőrizze az eredmények minőségét.
- Adatexportálás: Az adatfelirat kitöltése után exportálja az adatokat a kívánt formátumban. Az olyan platformok, mint a Nanonets, zökkenőmentes adatexportálást tesznek lehetővé különféle üzleti szoftveralkalmazásokba.
A teljes adatfeljegyzési folyamat néhány naptól több hétig tarthat, a projekt méretétől, összetettségétől és a rendelkezésre álló erőforrásoktól függően.
Az adatjegyzetek és az adatcímkézési eszközök szolgáltatásai
Az adatfelismerő eszközök döntő tényezők, amelyek előidézhetik vagy megszakíthatják az AI -projektet. Ami a pontos kimeneteket és eredményeket illeti, önmagában az adatkészletek minősége nem számít. Valójában az AI -modulok betanításához használt adatfelismerő eszközök óriási hatással vannak a kimenetekre.
Ezért elengedhetetlen, hogy kiválassza és használja a legfunkcionálisabb és legmegfelelőbb adatcímkézési eszközt, amely megfelel az üzleti vagy projekt igényeinek. De mi is az az adatfeldolgozó eszköz? Milyen célt szolgál? Vannak típusok? Nos, találjuk ki.
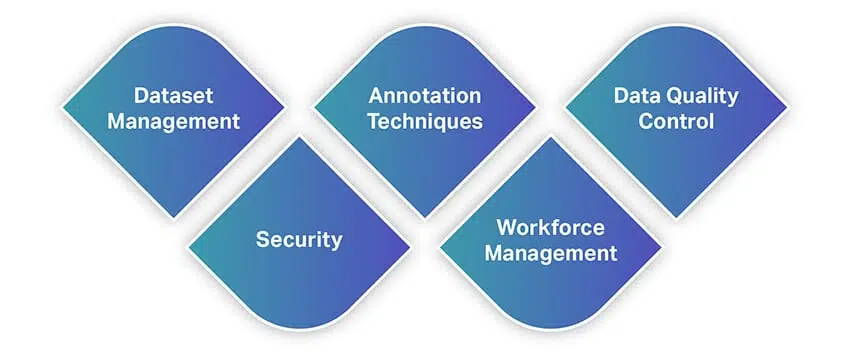
Más eszközökhöz hasonlóan az adatfelismerő eszközök számos funkciót és lehetőséget kínálnak. A funkciók gyors áttekintése érdekében itt találja a legalapvetőbb funkciók listáját, amelyekre figyelni kell az adatfeliratkozó eszköz kiválasztásakor.
Adatkészlet-kezelés
A használni kívánt adatfelismerő eszköznek támogatnia kell a kezében lévő adatkészleteket, és lehetővé kell tennie azok importálását a szoftverbe címkézés céljából. Tehát az adathalmazok kezelése az elsődleges szolgáltatáskínálat. A modern megoldások olyan funkciókat kínálnak, amelyek lehetővé teszik a nagy mennyiségű adat zökkenőmentes importálását, ugyanakkor lehetővé teszik az adatkészletek rendszerezését, szűrését, klónozását, egyesítését stb.
Az adathalmazok bevitele után a következő lépés a használható fájlok exportálása. Az Ön által használt eszköznek lehetővé kell tennie, hogy az adathalmazokat a megadott formátumban mentse, így betáplálhatja őket az ML modulokba.
Annotációs technikák
Erre készült vagy tervezték az adatfelismerő eszközt. Egy szilárd eszköznek számos feliratozási technikát kell kínálnia minden típusú adatkészlethez. Ez csak akkor lehetséges, ha egyedi megoldást fejleszt az igényeinek megfelelően. Eszközének lehetővé kell tennie a számítógépes látásból származó videók vagy képek jegyzetelését, az NLP -k és az átiratok stb. Hangját vagy szövegét. Ezt tovább finomítva, lehetőséget kell biztosítani a határoló dobozok, a szemantikai szegmentálás, a kockák, az interpoláció, az érzelemelemzés, a beszédrészek, a coreference megoldás és egyebek használatára.
Az avatatlanok számára vannak AI-alapú adatfeldolgozó eszközök is. Ezekhez AI -modulok tartoznak, amelyek önállóan tanulnak az annotátor munkamintáiból, és automatikusan megjegyzéseket fűznek a képekhez vagy a szöveghez. Ilyen
A modulok hihetetlen segítséget nyújthatnak az annotátorok számára, optimalizálhatják a megjegyzéseket, és akár minőségellenőrzést is végrehajthatnak.
Adatminőség -ellenőrzés
Ha már a minőségellenőrzésekről beszélünk, akkor számos adatfelismerő eszköz jelenik meg beágyazott minőségellenőrző modulokkal. Ezek lehetővé teszik a jegyzetelők számára, hogy jobban együttműködjenek csapattagjaikkal, és segítenek a munkafolyamatok optimalizálásában. Ezzel a funkcióval az annotátorok valós időben megjelölhetik és nyomon követhetik a megjegyzéseket vagy visszajelzéseket, nyomon követhetik a fájlokat módosító személyek mögötti személyazonosságot, visszaállíthatják a korábbi verziókat, választhatják a címkézési konszenzust és így tovább.
Biztonság
Mivel adatokkal dolgozik, a biztonságnak a legfontosabbnak kell lennie. Lehet, hogy bizalmas adatokkal dolgozik, például személyes adatokkal vagy szellemi tulajdonnal. Tehát az eszköznek légmentesen biztonságot kell nyújtania az adatok tárolása és megosztása tekintetében. Olyan eszközöket kell biztosítania, amelyek korlátozzák a hozzáférést a csapattagokhoz, megakadályozzák az illetéktelen letöltéseket és így tovább.
Ezenkívül meg kell felelni a biztonsági szabványoknak és protokolloknak.
Munkaerő menedzsment
Az adatfelismerő eszköz egyfajta projektmenedzsment -platform is, ahol feladatok rendelhetők a csapattagokhoz, együttműködési munka történhet, felülvizsgálatok lehetségesek és így tovább. Ezért a szerszámnak illeszkednie kell a munkafolyamatba és a folyamatba az optimális termelékenység érdekében.
Ezenkívül az eszköznek minimális tanulási görbével kell rendelkeznie, mivel az adatok megjegyzésének folyamata önmagában időigényes. Nem szolgál semmiféle céllal, ha túl sok időt tölt az eszköz elsajátításával. Tehát intuitívnak és zökkenőmentesnek kell lennie, hogy bárki gyorsan elkezdhesse.
Milyen előnyei vannak az adatjelölésnek?
Az adatjelölések kulcsfontosságúak a gépi tanulási rendszerek optimalizálása és a jobb felhasználói élmény biztosítása szempontjából. Íme az adatjelölés néhány fő előnye:
- Fokozott képzési hatékonyság: Az adatcímkézés segíti a gépi tanulási modellek jobb képzését, javítja az általános hatékonyságot és pontosabb eredményeket produkál.
- Megnövelt pontosság: A pontos megjegyzésekkel ellátott adatok biztosítják, hogy az algoritmusok hatékonyan alkalmazkodjanak és tanuljanak, ami nagyobb pontosságot eredményez a jövőbeni feladatokban.
- Csökkentett emberi beavatkozás: A fejlett adatfeljegyzési eszközök jelentősen csökkentik a kézi beavatkozás szükségességét, ésszerűsítik a folyamatokat és csökkentik a kapcsolódó költségeket.
Így az adatfeljegyzések hozzájárulnak a hatékonyabb és pontosabb gépi tanulási rendszerek kialakításához, miközben minimalizálják az AI-modellek betanításához hagyományosan szükséges költségeket és manuális erőfeszítéseket.
Adatmegjegyzés eszköz létrehozása vagy nem
Az egyik kritikus és átfogó kérdés, amely felmerülhet az adatjegyzetek vagy az adatcímkézési projektek során, az a választás, hogy funkcionalitást építenek vagy vásárolnak-e ezekhez a folyamatokhoz. Ez többször felmerülhet a projekt különböző szakaszaiban, vagy a program különböző szegmenseihez kapcsolódhat. Annak eldöntésekor, hogy a rendszert belsőleg építik-e fel, vagy a gyártókra támaszkodnak, mindig kompromisszumot kell kötni.

Amint azt valószínűleg most megmondhatja, az adatjegyzések összetett folyamat. Ugyanakkor szubjektív folyamat is. Ez azt jelenti, hogy nincs egyetlen válasz arra a kérdésre, hogy vásároljon-e vagy építsen-e egy adat annotációs eszközt. Számos tényezőt figyelembe kell venni, és fel kell tennie néhány kérdést magának, hogy megértse követelményeit és felismerje, hogy valóban meg kell-e vásárolnia vagy meg kell építenie.
Ennek egyszerűsítése érdekében íme néhány tényező, amelyet figyelembe kell vennie.
A célod
Az első elem, amelyet meg kell határoznia, a mesterséges intelligencia és a gépi tanulási koncepciók célja.
- Miért valósítja meg ezeket a vállalkozásában?
- Megoldják a valós problémákat, amelyekkel az ügyfelek szembesülnek?
- Készítenek valamilyen front-end vagy backend folyamatot?
- Az AI segítségével új funkciókat vezet be, vagy optimalizálja a meglévő webhelyet, alkalmazást vagy modult?
- Mit csinál versenytársa a szegmensében?
- Van elegendő olyan esete, amelyekhez AI beavatkozás szükséges?
Az ezekre adott válaszok összegyűjtik gondolatait - amelyek jelenleg mindenhol előfordulhatnak - egy helyre gyűjthetik, és nagyobb tisztaságot adnak Önnek.
AI adatgyűjtés / licenc
Az AI modellek csak egy elemet igényelnek a működéshez - az adatokat. Meg kell határoznia, hogy honnan tud hatalmas mennyiségű földi igazságot előállítani. Ha vállalkozása nagy mennyiségű adatot állít elő, amelyeket fel kell dolgozni az üzleti, működési, versenytársak kutatásának, a piaci volatilitási elemzéseknek, az ügyfelek magatartásának tanulmányozásának és egyéb fontosabb betekintéseinek érdekében, akkor szüksége van egy adatfelismerő eszközre. Azonban figyelembe kell vennie a generált adatok mennyiségét is. Mint korábban említettük, az AI -modell csak annyira hatékony, mint a betáplált adatok minősége és mennyisége. Tehát a döntéseinek mindig ettől a tényezőtől kell függnie.
Ha nem rendelkezik megfelelő adatokkal az ML-modellek kiképzéséhez, a gyártók nagyon hasznosak lehetnek, és segítséget nyújthatnak az ML-modellek képzéséhez szükséges megfelelő adatsorok licencelésében. Bizonyos esetekben az eladó által biztosított érték egy része magában foglalja mind a technikai hozzáértést, mind pedig a projekt sikerét elősegítő erőforrásokhoz való hozzáférést.
Érték
Egy másik alapvető feltétel, amely valószínűleg befolyásol minden egyes tényezőt, amelyet jelenleg tárgyalunk. Annak kérdésére, hogy kell-e felépítenie vagy megvásárolnia az adatjegyzeteket, könnyen megoldható, ha megérti, hogy van-e elegendő költségkerete a költésre.
Megfelelési bonyolultságok
 Az értékesítők rendkívül hasznosak lehetnek az adatvédelem és a bizalmas adatok helyes kezelése terén. Az ilyen típusú felhasználási esetek egyike olyan kórházat vagy egészségüggyel kapcsolatos vállalkozást érint, amely a gépi tanulás erejét szeretné kihasználni, anélkül, hogy veszélyeztetné a HIPAA és más adatvédelmi szabályok betartását. Az orvosi területen kívül is olyan törvények szigorítják az adatkészletek ellenőrzését, amelyek fokozottabb éberséget követelnek meg a vállalati érdekeltek részéről.
Az értékesítők rendkívül hasznosak lehetnek az adatvédelem és a bizalmas adatok helyes kezelése terén. Az ilyen típusú felhasználási esetek egyike olyan kórházat vagy egészségüggyel kapcsolatos vállalkozást érint, amely a gépi tanulás erejét szeretné kihasználni, anélkül, hogy veszélyeztetné a HIPAA és más adatvédelmi szabályok betartását. Az orvosi területen kívül is olyan törvények szigorítják az adatkészletek ellenőrzését, amelyek fokozottabb éberséget követelnek meg a vállalati érdekeltek részéről.
Munkaerő
Az adatok megjegyzéseihez szakképzett munkaerőre van szükség a vállalkozás méretétől, méretétől és tartományától függetlenül. Még akkor is, ha minden nap minimális adatot állít elő, szüksége van adatszakértőkre, hogy dolgozzák fel adatait a címkézéshez. Tehát most fel kell ismernie, hogy rendelkezik -e a szükséges munkaerővel. Ha igen, akkor jártas -e a szükséges eszközökben és technikákban, vagy szükség van -e továbbképzésre? Ha továbbképzésre van szükségük, van -e elegendő költségvetése a képzésükhöz?
Ezenkívül a legjobb adatmegjelölési és adatcímkézési programok számos témakör vagy szakterület szakértőjét veszik fel és csoportosítják őket demográfiai adatok, például életkor, nem és szakterület szerint - vagy gyakran a lokalizált nyelvek szerint. Ismét itt beszélünk a Shaip-nál arról, hogy a megfelelő embereket a megfelelő ülésekre helyezzük, ezáltal a megfelelő ember-a-hurokban folyamatokat hajtjuk, amelyek az ön programozási erőfeszítéseit sikerhez vezetik.
Kis és nagy projektműveletek és költségküszöbök
Sok esetben a szállítói támogatás inkább egy kisebb projekthez vagy kisebb projektfázisokhoz kínálkozik. Amikor a költségek szabályozhatók, a vállalat profitálhat az outsourcingból, hogy hatékonyabbá tegye az adatok megjegyzéseit vagy az adatok címkézését.
A vállalatok fontos küszöbértékeket is megvizsgálhatnak - ahol sok gyártó a költségeket az elfogyasztott adatmennyiséghez vagy más erőforrás -referenciaértékekhez köti. Tegyük fel például, hogy egy vállalat regisztrált egy szállítóval, hogy elvégezze a tesztkészletek beállításához szükséges unalmas adatbevitelt.
Lehet rejtett küszöbérték a megállapodásban, ahol például az üzleti partnernek ki kell vennie az AWS adattárolásának újabb blokkját, vagy valamilyen más szolgáltatási elemet az Amazon Web Services-től, vagy más harmadik féltől származó szállítótól. Magasabb költségek formájában ezt továbbadják az ügyfélnek, és ez az árcédulát nem teszi elérhetővé az ügyfél számára.
Ezekben az esetekben a szállítóktól kapott szolgáltatások mérése segít fenntartani a projektet. A megfelelő hatókör megléte biztosítja, hogy a projekt költségei ne lépjék túl az adott cég számára ésszerű vagy megvalósítható mértéket.
Nyílt forráskódú és ingyenes szoftver alternatívák
 A teljes szállítói támogatás néhány alternatívája magában foglalja a nyílt forráskódú szoftverek vagy akár az ingyenes szoftverek használatát az adatok feliratozásához vagy címkézési projektekhez. Itt van egyfajta középút, ahol a vállalatok nem mindent hoznak létre a semmiből, de elkerülik azt is, hogy túlságosan támaszkodjanak a kereskedelmi forgalmazókra.
A teljes szállítói támogatás néhány alternatívája magában foglalja a nyílt forráskódú szoftverek vagy akár az ingyenes szoftverek használatát az adatok feliratozásához vagy címkézési projektekhez. Itt van egyfajta középút, ahol a vállalatok nem mindent hoznak létre a semmiből, de elkerülik azt is, hogy túlságosan támaszkodjanak a kereskedelmi forgalmazókra.
A nyílt forráskódú do-it-yourself mentalitás maga is egyfajta kompromisszum - a mérnökök és a belső emberek kihasználhatják a nyílt forráskódú közösség előnyeit, ahol a decentralizált felhasználói bázisok saját fajtájú támogatást kínálnak. Nem olyan lesz, mint amit egy szállítótól kap - nem kap 24 órás könnyű segítséget vagy válaszokat a kérdésekre belső kutatás elvégzése nélkül -, de az árcímke alacsonyabb.
Tehát, a nagy kérdés - Mikor érdemes vásárolni egy adatmegjelölő eszközt:
Mint sokféle csúcstechnológiás projekt esetében, ez a fajta elemzés - mikor kell építeni és mikor kell megvásárolni - elkötelezett gondolkodást és megfontolást igényel e projektek beszerzésének és kezelésének módjáról. Azok a kihívások, amelyekkel a legtöbb vállalat szembesül az AI / ML projektekkel kapcsolatban, amikor figyelembe veszi az „építkezés” opciót, nem csak a projekt építési és fejlesztési részeiről szól. Gyakran óriási tanulási görbe van ahhoz, hogy eljuthassunk arra a pontra, ahol az igazi AI / ML fejlődés megtörténhet. Új AI / ML csapatok és kezdeményezések révén az „ismeretlen ismeretlenek” száma jóval meghaladja az „ismert ismeretlenek” számát.
| Épít | Vásárlás |
|---|---|
Előnyök:
| Előnyök:
|
Hátrányok:
| Hátrányok:
|
A dolgok még egyszerűbbé tétele érdekében vegye figyelembe a következő szempontokat:
- amikor hatalmas mennyiségű adattal dolgozik
- amikor különféle adatfajtákon dolgozik
- amikor a modellekhez vagy megoldásokhoz kapcsolódó funkciók megváltozhatnak vagy fejlődhetnek a jövőben
- amikor homályos vagy általános használati esete van
- amikor világos elképzelésre van szüksége az adatjelölő eszköz telepítésének költségeiről
- és amikor nincs megfelelő munkaerő vagy szakképzett szakértő az eszközök kidolgozásához, és minimális tanulási görbét keres
Ha válaszai ellentétesek lennének ezekkel a forgatókönyvekkel, akkor az eszköz felépítésére kell összpontosítania.
Hogyan válasszuk ki a megfelelő adatfeljegyzési eszközt a projekthez
Ha ezt olvassa, ezek az ötletek izgalmasnak tűnnek, és egyértelműen könnyebben elmondhatók, mint megtenni. Tehát hogyan lehet kiaknázni a rengeteg már létező adat annotációs eszközt? Tehát a következő lépés a megfelelő adat annotációs eszköz kiválasztásával járó tényezők mérlegelése.
Néhány évvel ezelőttivel ellentétben a piac ma rengeteg adat annotációs eszközzel fejlődött. A vállalkozásoknak több lehetőségük van arra, hogy külön igényeik alapján válasszanak egyet. De minden egyes eszköznek megvan a maga előnye és hátránya. A bölcs döntéshez objektív utat kell választani a szubjektív követelményektől is.
Nézzünk meg néhány fontos tényezőt, amelyet figyelembe kell vennie a folyamat során.
Felhasználási esetének meghatározása
A megfelelő adat annotációs eszköz kiválasztásához meg kell határoznia a felhasználási esetet. Tudnia kell, ha követelménye szöveget, képet, videót, hangot vagy az összes adattípus keverékét foglalja magában. Vannak önálló eszközök, amelyeket megvásárolhat, és vannak holisztikus eszközök, amelyek lehetővé teszik az adatkészleteken végzett különféle műveletek végrehajtását.
A mai eszközök intuitívak, és lehetőséget kínálnak a tárolási lehetőségekre (hálózat, helyi vagy felhő), az annotációs technikákra (hang, kép, 3D és még sok más) és számos más szempontra. Választhat egy eszközt a saját igényei alapján.
Minőség-ellenőrzési szabványok kialakítása
 Ez egy döntő tényező, amelyet figyelembe kell venni, mivel a mesterséges intelligencia-modelljeinek célja és hatékonysága az Ön által meghatározott minőségi előírásoktól függ. Az audithoz hasonlóan el kell végeznie a betáplált adatok és az elért eredmények minőségi ellenőrzését annak megértése érdekében, hogy modelljeit megfelelő módon és megfelelő célokra oktatják-e. A kérdés azonban az, hogy szándékozik-e minőségi normákat megállapítani?
Ez egy döntő tényező, amelyet figyelembe kell venni, mivel a mesterséges intelligencia-modelljeinek célja és hatékonysága az Ön által meghatározott minőségi előírásoktól függ. Az audithoz hasonlóan el kell végeznie a betáplált adatok és az elért eredmények minőségi ellenőrzését annak megértése érdekében, hogy modelljeit megfelelő módon és megfelelő célokra oktatják-e. A kérdés azonban az, hogy szándékozik-e minőségi normákat megállapítani?
Mint sokféle munkánál, sok ember végezhet adatmegjegyzéseket és címkézést, de különböző fokozatú sikerrel. Amikor szolgáltatást kér, nem ellenőrzi automatikusan a minőség-ellenőrzés szintjét. Ezért változnak az eredmények.
Tehát konszenzusos modellt kíván telepíteni, ahol az annotátorok visszajelzéseket adnak a minőségről, és a korrekciós intézkedéseket azonnal meghozzák? Vagy inkább a minta felülvizsgálatát, az arany szabványokat vagy a kereszteződést részesíti előnyben a szakszervezeti modellekkel szemben?
A legjobb vételi terv biztosítja a minőségellenőrzést a kezdetektől azáltal, hogy a végleges szerződés megkötése előtt szabványokat határoz meg. Ennek megállapításakor nem szabad figyelmen kívül hagynia a hiba margókat sem. A kézi beavatkozást nem lehet teljesen elkerülni, mivel a rendszerek kötelesek legfeljebb 3% -os hibákat produkálni. Ez előre viszi a munkát, de megéri.
Ki jegyzi fel adatait?
A következő fő tényező azon múlik, hogy ki jegyzi fel az adatait. Házon belüli csapatot tervez, vagy inkább kiszervezi? Ha kiszervezi, akkor törvényességeket és megfelelőségi intézkedéseket kell figyelembe vennie az adatokkal kapcsolatos adatvédelmi és titoktartási aggályok miatt. És ha van házon belüli csapata, mennyire hatékonyak egy új eszköz megtanulásában? Mennyi az idő, hogy piacra lépjen termékével vagy szolgáltatásával? Megfelelő minőségi mutatókkal és csapatokkal rendelkezik az eredmények jóváhagyásához?
Az eladó vs. Partner-vita
 Az adatok kommentálása együttműködési folyamat. Függőségeket és bonyolultságokat foglal magában, mint például az interoperabilitás. Ez azt jelenti, hogy bizonyos csapatok mindig párhuzamosan működnek egymással, és az egyik csapat az Ön szállítója lehet. Ezért a kiválasztott eladó vagy partner ugyanolyan fontos, mint az adatcímkézéshez használt eszköz.
Az adatok kommentálása együttműködési folyamat. Függőségeket és bonyolultságokat foglal magában, mint például az interoperabilitás. Ez azt jelenti, hogy bizonyos csapatok mindig párhuzamosan működnek egymással, és az egyik csapat az Ön szállítója lehet. Ezért a kiválasztott eladó vagy partner ugyanolyan fontos, mint az adatcímkézéshez használt eszköz.
Ezzel a tényezővel figyelembe kell venni az olyan szempontokat, mint az adatok és szándékok bizalmas kezelésének képessége, a visszajelzések elfogadásának és a visszacsatolással való munka szándéka, proaktív tevékenység az adatigénylés terén, a műveletek rugalmassága és még sok más. . Bevettük a rugalmasságot, mert az adat annotációs követelmények nem mindig lineárisak vagy statikusak. Ezek változhatnak a jövőben, ha tovább bővíti vállalkozását. Ha jelenleg csak szöveges alapú adatokkal foglalkozik, érdemes a hangosítás vagy a hangadatok jegyzetekkel ellátása közben a méretezés során, és támogatásának készen kell állnia a látókörük bővítésére.
Az eladó bevonása
Az eladói részvétel értékelésének egyik módja a kapott támogatás.
Bármely vásárlási tervnek figyelembe kell vennie ezt az összetevőt. Hogyan fog kinézni a támogatás a földön? Kik lesznek az érdekelt felek és az emberek az egyenlet mindkét oldalán?
Vannak olyan konkrét feladatok is, amelyeknek ki kell fejteniük, hogy mi (vagy lesz) az eladó részvétele. Különösen egy adatjelölés vagy adatcímkézési projekt esetében az eladó aktívan szolgáltatja-e a nyers adatokat, vagy sem? Ki fog eljárni tárgyszakértőként, és ki alkalmazza őket alkalmazottként vagy független vállalkozóként?
Esettanulmányok
Íme néhány konkrét esettanulmányi példa, amelyek arról szólnak, hogy az adatok megjegyzései és az adatok címkézése hogyan működnek a helyszínen. A Shaipnél gondot fordítunk arra, hogy a legmagasabb szintű minőséget és kiváló eredményeket biztosítsuk az adatok jegyzetelésében és az adatok címkézésében.
Az adat annotációval és az adatcímkézéssel kapcsolatos standard eredmények fenti vitájának nagy része feltárja, hogyan közelítjük meg az egyes projekteket, és mit kínálunk azoknak a vállalatoknak és érdekelt feleknek, akikkel együtt dolgozunk.
Esettanulmányok, amelyek bemutatják ennek működését:

Egy klinikai adatengedélyezési projekt során a Shaip csapata több mint 6,000 órányi hanganyagot dolgozott fel, eltávolítva az összes védett egészségügyi információt (PHI), és az egészségügyi beszédfelismerési modellek számára HIPAA-kompatibilis tartalmat hagyva működni.
Ilyen esetekben a kritériumok és az eredmények osztályozása a fontos. A nyers adatok audio formátumban vannak, és szükség van a felek azonosításának megszüntetésére. Például a NER-elemzés során a kettős cél a tartalom azonosításának és megjegyzésének feloldása.
Egy másik esettanulmány mélyreható társalgási AI képzési adatok projekt, amelyet 3,000 hetes időszak alatt 14 nyelvészsel fejeztünk be. Ez 27 nyelven képzési adatok előállításához vezetett, hogy olyan többnyelvű digitális asszisztenseket fejlesszenek ki, amelyek képesek kezelni az emberi interakciókat az anyanyelvek széles választékán.
Ebben a konkrét esettanulmányban nyilvánvaló volt, hogy a megfelelő embert kell a megfelelő székbe ültetni. A tantárgyi szakértők és a tartalombeviteli operátorok nagy száma azt jelentette, hogy szervezésre és eljárási egyszerűsítésre volt szükség ahhoz, hogy a projekt egy meghatározott ütemterven belül megvalósuljon. Csapatunk az adatgyűjtés és az azt követő folyamatok optimalizálása révén nagy előnnyel tudta legyőzni az ipari színvonalat.
Az esettanulmányok egyéb típusai olyan dolgokat tartalmaznak, mint a botok képzése és a gépi tanuláshoz szükséges szöveges kommentárok. Megint szöveges formátumban továbbra is fontos az azonosított felek kezelése az adatvédelmi törvények szerint, és a nyers adatok rendezése a célzott eredmények elérése érdekében.
Más szóval, a több adattípus és formátum közötti együttműködés során a Shaip ugyanazt a létfontosságú sikert mutatta be, amikor ugyanazokat a módszereket és elveket alkalmazta mind a nyers adatokra, mind az adatengedélyezési üzleti forgatókönyvekre.