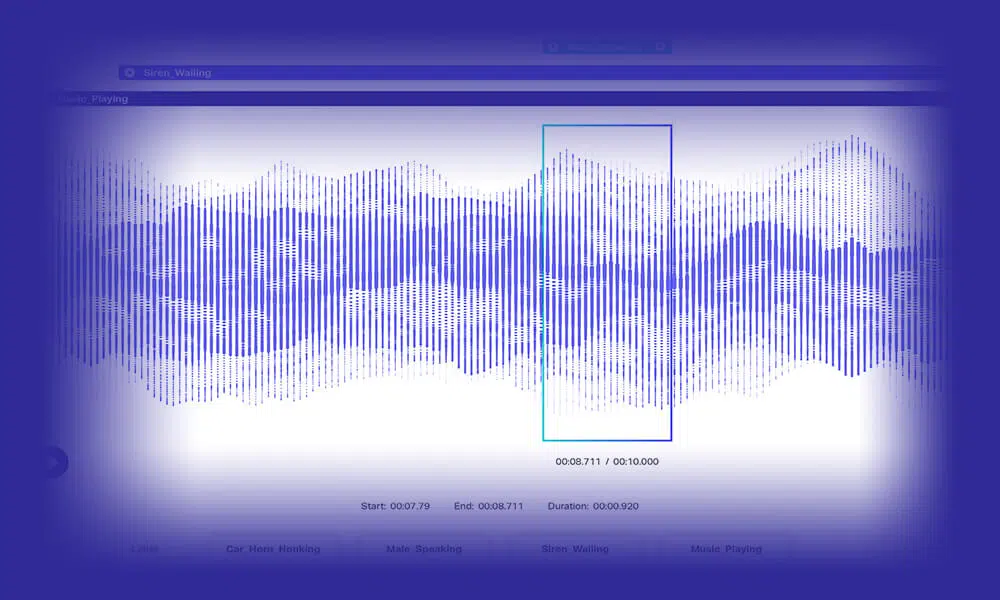


Audio átírás
Fejlesszen intelligens NLP modelleket azáltal, hogy teherautónyi pontosan átírt beszéd-/ hangadatot táplál be. A Shaipnél szélesebb választék közül választhatunk, beleértve a normál hangot, a szó szerinti és a többnyelvű átírást. Ezenkívül a modelleket további hangszóróazonosítókkal és időbélyegzési adatokkal oktathatja.
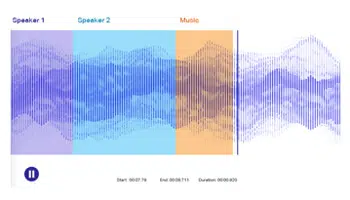
Beszédcímkézés
A beszéd- vagy hangcímkézés egy szabványos megjegyzési technika, amely a hangok elválasztására és a specifikus metaadatokkal való címkézésre vonatkozik. Ennek a technikának a lényege magában foglalja a hangok ontológiai azonosítását egy hangrészletből, és pontos jegyzetelését, hogy az oktatási adathalmazokat befogadóbbá tegye

Audio osztályozás
A beszédjegyzeteket készítő cégek használják a mesterséges intelligencia tökéletesítésére, a hangfelvételek tartalom szerinti elemzésére. A hangbesorolásokkal a gépek azonosítani tudják a hangokat és a hangokat, miközben képesek különbséget tenni a kettő között, egy proaktívabb képzési rendszer részeként.

Többnyelvű audio adatszolgáltatások
A többnyelvű hangadatok gyűjtése csak akkor hasznos, ha az annotátorok ennek megfelelően címkézhetik és szegmentálhatják azokat. Itt hasznosak a többnyelvű audioadat -szolgáltatások, mivel a nyelv sokféleségén alapuló, megjegyzésekkel ellátott beszédről van szó, amelyet a megfelelő AI -k tökéletesen azonosítanak és értelmeznek.

Természetes nyelv
Kifejezés
Az NLU az emberi beszéd jegyzetelésével foglalkozik a legapróbb részletek osztályozásához is, mint szemantika, nyelvjárások, kontextus, stressz stb. A megjegyzésekkel ellátott adatok ezen formája értelmes a virtuális asszisztensek és a chatbotok jobb képzésében.
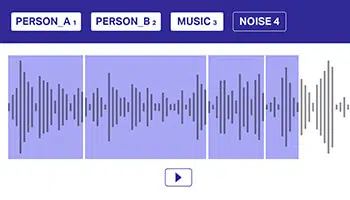
Többcímke
Jegyzet
Az audioadatok több címke használatával történő megjegyzése fontos, hogy segítse a modelleket az egymást átfedő hangforrások megkülönböztetésében. Ebben a megközelítésben egy audio adathalmaz egy vagy több osztályhoz tartozhat, amelyeket a modellnek kifejezetten át kell adni a jobb döntéshozatal érdekében.

Hangszóró átméretezése
Ez magában foglalja a bemeneti hangfájl felosztását az egyes hangszórókhoz társított homogén szegmensekre. A naplózás a hangszórók határainak azonosítását és az audiofájlok szegmensekbe történő csoportosítását jelenti a különálló hangszórók számának meghatározásához. Ez a folyamat segít automatizálni a beszélgetések elemzését és a call centeres párbeszédek, orvosi és jogi beszélgetések, valamint találkozók átírását.

Fonetikus átírás
Ellentétben a hagyományos átírással, amely a hangot szavak sorozatává alakítja, a fonetikus átírás megjegyzi a szavak kiejtését, és fonetikus szimbólumok segítségével vizuálisan ábrázolja a hangokat. A fonetikus átírás megkönnyíti ugyanazon nyelv kiejtésének különbségét több dialektusban.

Emberek (People)
Dedikált és kiképzett csapatok:
- Több mint 30,000 munkatárs az adatok létrehozásához, címkézéséhez és minőségbiztosításához
- Hitelesített projektmenedzsment csapat
- Tapasztalt termékfejlesztő csapat
- Tehetséggondozási és beszállítói csapat

folyamat
A legnagyobb hatékonyságot az alábbiak biztosítják:
- Robusztus 6 Sigma Stage-Gate folyamat
- 6 Sigma fekete övből álló elkötelezett csapat - A legfontosabb folyamattulajdonosok és a minőségi megfelelés
- Folyamatos fejlesztés és visszacsatolási hurok

Emelvény
A szabadalmaztatott platform előnyöket kínál:
- Webalapú végpontok közötti platform
- Kifogástalan minőség
- Gyorsabb TAT
- Zökkenőmentes szállítás
Emberek (People)
Dedikált és kiképzett csapatok:
- Több mint 30,000 munkatárs az adatok létrehozásához, címkézéséhez és minőségbiztosításához
- Hitelesített projektmenedzsment csapat
- Tapasztalt termékfejlesztő csapat
- Tehetséggondozási és beszállítói csapat
folyamat
A legnagyobb hatékonyságot az alábbiak biztosítják:
- Robusztus 6 Sigma Stage-Gate folyamat
- 6 Sigma fekete övből álló elkötelezett csapat - A legfontosabb folyamattulajdonosok és a minőségi megfelelés
- Folyamatos fejlesztés és visszacsatolási hurok
Emelvény
A szabadalmaztatott platform előnyöket kínál:
- Webalapú végpontok közötti platform
- Kifogástalan minőség
- Gyorsabb TAT
- Zökkenőmentes szállítás

Szövegjegyzet
Szolgáltatások
Szakterületünk a szöveges adatokkal kapcsolatos képzések készítése a kimerítő adathalmazok jegyzetelésével, az entitások megjegyzéseinek, szöveges besorolásának, érzelmi megjegyzéseknek és más releváns eszközöknek a használatával.

Kép megjegyzés
Szolgáltatások
Büszkék vagyunk a címkézésre, a szegmentált képadatokra, hogy kiképezzük a számítógépes látásmodelleket. Néhány releváns technika magában foglalja a határfelismerést és a képek osztályozását.

Videó kommentárja
Szolgáltatások
A Shaip csúcsminőségű videócímkézési szolgáltatásokat kínál a Computer Vision modellek oktatásához. A cél az, hogy az adatkészletek használhatók legyenek olyan eszközökkel, mint a mintafelismerés, az objektumfelismerés stb.


