



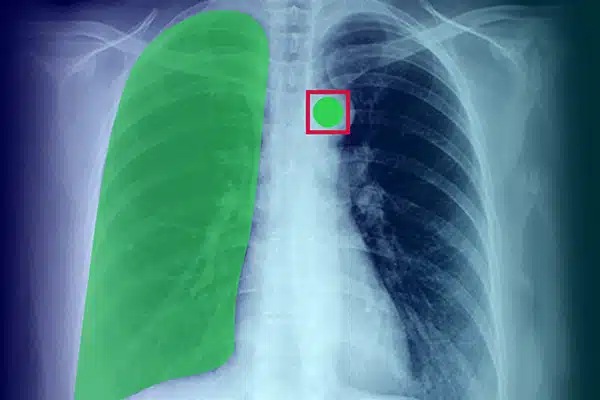
Kép megjegyzés
Az orvosi mesterséges intelligencia javítása a röntgen-, CT- és MRI-vizsgálatokból származó vizuális adatok megjegyzéseivel. Gondoskodjon arról, hogy az AI-modellek kiválóan teljesítsenek a diagnosztikában és a kezelésben, szakértői adatcímkézés alapján. Jobb eredményeket érhet el a betegeknél a kiváló képalkotási betekintések segítségével.
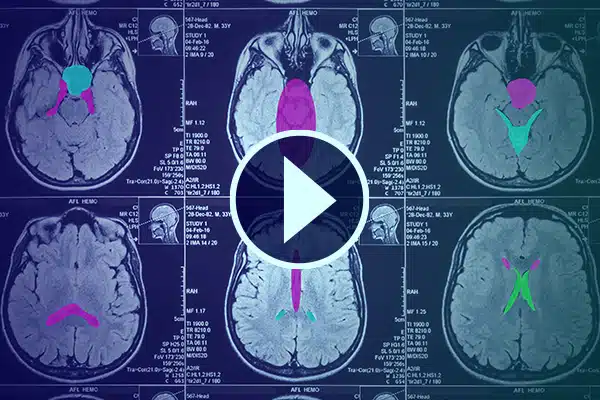
Videó kommentárja
Fejlessze az AI-t az egészségügyben részletes videokommentárokkal. Élesítse az AI-tanulást az orvosi felvételeken található osztályozásokkal és szegmentációkkal. Javítsa a sebészeti mesterséges intelligencia és a betegek monitorozását a jobb egészségügyi ellátás és diagnosztika érdekében.
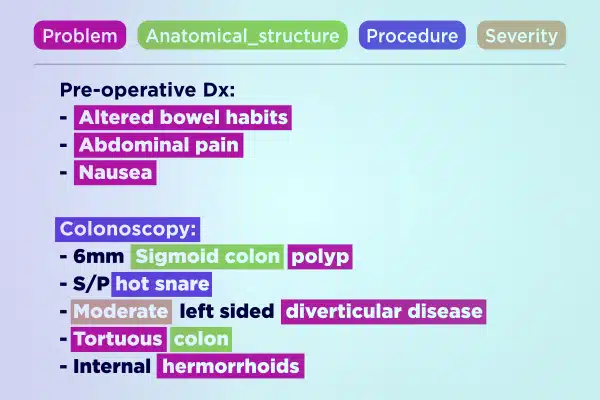
Szövegjegyzet
Egyszerűsítse az orvosi mesterséges intelligencia fejlesztését szakszerűen jegyzett szöveges adatokkal. Gyorsan elemezhet és gazdagíthat hatalmas szövegkötetet, a kézzel írt jegyzetektől a biztosítási jelentésekig. Biztosítson pontos és megvalósítható betekintést az egészségügyi fejlesztések érdekében.

Hangjegyzet
Használja ki az NLP szakértelmét az orvosi hangadatok pontos megjegyzéséhez és címkézéséhez. Készítsen hangalapú rendszereket a zökkenőmentes klinikai műveletekhez, és integrálja a mesterséges intelligenciát különböző hangvezérelt egészségügyi termékekbe. Növelje a diagnosztikai pontosságot a hangadatok szakértő kezelésével.

Orvosi kódolás
Egyszerűsítse az orvosi dokumentációt azáltal, hogy AI orvosi kódolással univerzális kódokká alakítja. Biztosítsa a pontosságot, javítsa a számlázási hatékonyságot, és támogassa a zökkenőmentes egészségügyi szolgáltatások nyújtását a korszerű mesterséges intelligencia-segítséggel az orvosi feljegyzések kódolásában.

1 fázis: Szakterületi szakértelem (A hatókör és a megjegyzésekkel kapcsolatos irányelvek megértése)

2 fázis: A projekthez megfelelő erőforrások képzése

3 fázis: A megjegyzésekkel ellátott dokumentumok visszacsatolási ciklusa és minőségbiztosítása
Radiológia
Radiológiai képannotációs szolgáltatásunk élesíti az AI-diagnosztikát, és további szakértelemre tesz szert. Minden röntgen-, MRI- és CT-vizsgálatot aprólékosan felcímkéznek, és a téma szakértője felülvizsgál. Ez az extra lépés a képzésben és a felülvizsgálatban fokozza a mesterséges intelligencia azon képességét, hogy észlelje a rendellenességeket és a betegségeket. Növeli a pontosságot ügyfeleinknek való kiszállítás előtt.

Kardiológia
Kardiológiára fókuszáló képannotációnk élesíti az AI-diagnosztikát. Kardiológiai szakértőket vonunk be, akik komplex, szívvel kapcsolatos képeket címkéznek fel, és kiképezik AI-modelleinket. Mielőtt adatokat küldenénk az ügyfeleknek, ezek a szakemberek minden egyes képet átnéznek, hogy biztosítsák a kiváló pontosságot. Ez a folyamat lehetővé teszi a mesterséges intelligencia pontosabb észlelését a szívbetegségekben.
Fogászat
A fogászatban kínált képannotációs szolgáltatásunk a fogászati képeket címkézi az AI diagnosztikai eszközök fejlesztése érdekében. A fogszuvasodás, az illesztési problémák és egyéb fogászati állapotok pontos azonosításával kkv-ink lehetővé teszik a mesterséges intelligencia javítását a betegek kimenetelének javításában, és támogatják a fogorvosokat a kezelés pontos tervezésében és a korai felismerésben.


















Emberek (People)
Dedikált és kiképzett csapatok:
- Több mint 30,000 munkatárs az adatok létrehozásához, címkézéséhez és minőségbiztosításához
- Hitelesített projektmenedzsment csapat
- Tapasztalt termékfejlesztő csapat
- Tehetséggondozási és beszállítói csapat

folyamat
A legnagyobb hatékonyságot az alábbiak biztosítják:
- Robusztus 6 Sigma Stage-Gate folyamat
- 6 Sigma fekete övből álló elkötelezett csapat - A legfontosabb folyamattulajdonosok és a minőségi megfelelés
- Folyamatos fejlesztés és visszacsatolási hurok

Emelvény
A szabadalmaztatott platform előnyöket kínál:
- Webalapú végpontok közötti platform
- Kifogástalan minőség
- Gyorsabb TAT
- Zökkenőmentes szállítás



