

Mik azok a nagy nyelvi modellek?
A nagy nyelvi modellek (LLM-ek) fejlett mesterséges intelligencia-rendszerek, amelyeket emberi szöveg feldolgozására, megértésére és előállítására terveztek. Mélytanulási technikákon alapulnak, és hatalmas adatkészleteken dolgoznak, amelyek általában több milliárd szót tartalmaznak különféle forrásokból, például webhelyekről, könyvekről és cikkekről. Ez a kiterjedt képzés lehetővé teszi az LLM-ek számára, hogy megértsék a nyelv, a nyelvtan, a szövegkörnyezet árnyalatait és még az általános ismeretek egyes aspektusait is.
Egyes népszerű LLM-ek, mint például az OpenAI GPT-3, egyfajta neurális hálózatot alkalmaznak, amelyet transzformátornak neveznek, amely lehetővé teszi számukra, hogy figyelemre méltó szakértelemmel kezeljék az összetett nyelvi feladatokat. Ezek a modellek a feladatok széles skáláját képesek ellátni, például:
- Kérdések megválaszolása
- Összefoglaló szöveg
- Nyelvek fordítása
- Tartalom generálása
- Még a felhasználókkal folytatott interaktív beszélgetések is
Ahogy az LLM-k folyamatosan fejlődnek, nagy lehetőségek rejlenek bennük a különféle alkalmazások fejlesztésére és automatizálására az iparágakban, az ügyfélszolgálattól és a tartalomkészítéstől az oktatásig és a kutatásig. Ugyanakkor etikai és társadalmi aggályokat is felvetnek, mint például az elfogult viselkedés vagy a visszaélés, amelyeket a technológia fejlődésével kezelni kell.

Népszerű példák nagy nyelvi modellekre
Íme néhány kiemelkedő példa a különböző iparági vertikumokban széles körben használt LLM-ekre:
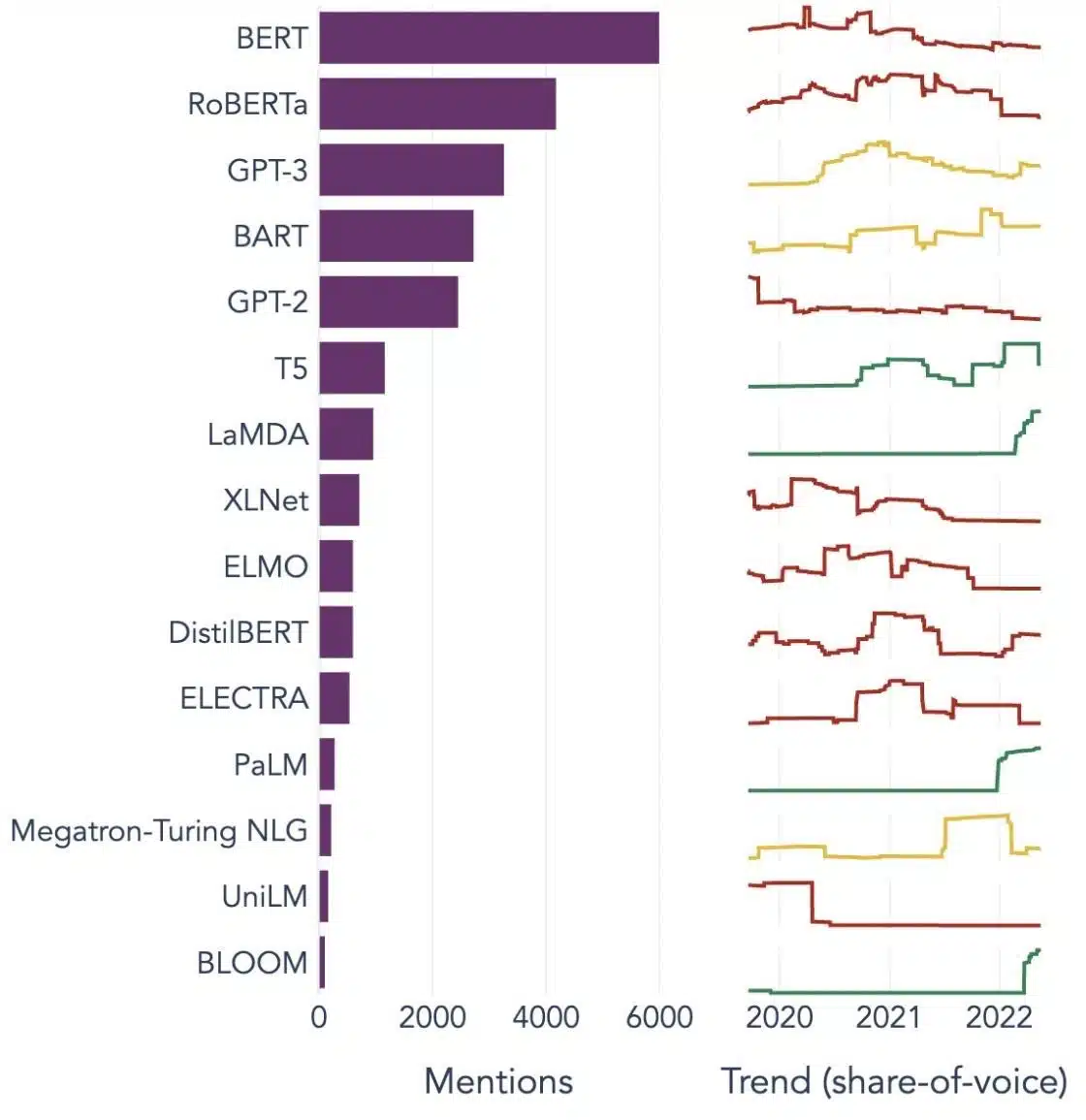
Image Source: Adattudomány felé
Hogyan képezik az LLM modelleket?
A nagy nyelvi modellek (LLM) betanítása meglehetősen nagy teljesítmény, amely több döntő lépést foglal magában. Íme a folyamat leegyszerűsített, lépésről lépésre történő leírása:
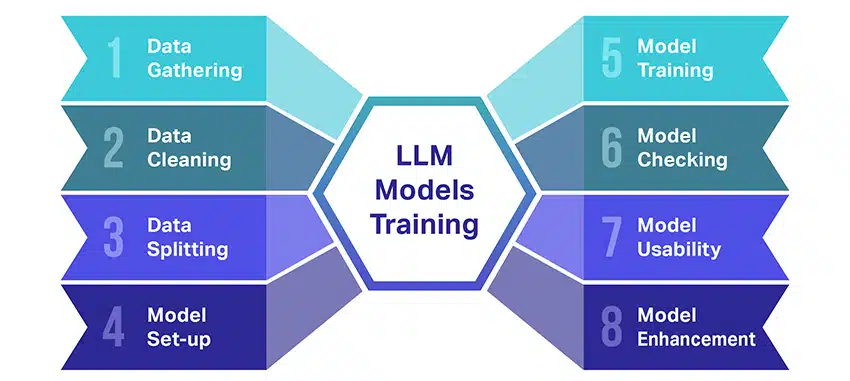
- Szöveges adatok gyűjtése: Az LLM képzése hatalmas mennyiségű szöveges adat összegyűjtésével kezdődik. Ezek az adatok származhatnak könyvekből, webhelyekről, cikkekből vagy közösségi média platformokról. A cél az emberi nyelv gazdag sokszínűségének megragadása.
- Az adatok tisztítása: A nyers szöveges adatokat ezután egy előfeldolgozásnak nevezett folyamatban rendezik. Ez magában foglal olyan feladatokat, mint a nem kívánt karakterek eltávolítása, a szöveg kisebb részekre, úgynevezett tokenekre bontása, és az egésznek olyan formátumba állítása, amellyel a modell képes működni.
- Az adatok felosztása: Ezután a tiszta adatokat két csoportra osztják. Az egyik halmazt, a betanítási adatokat használjuk fel a modell betanításához. A másik halmazt, az érvényesítési adatokat később a modell teljesítményének tesztelésére használjuk fel.
- A modell beállítása: Ezután meghatározzák az LLM szerkezetét, amelyet architektúrának neveznek. Ez magában foglalja a neurális hálózat típusának kiválasztását és a különféle paraméterek, például a hálózaton belüli rétegek és rejtett egységek számának meghatározását.
- A modell betanítása: A tényleges képzés most kezdődik. Az LLM-modell úgy tanul, hogy megnézi a betanítási adatokat, előrejelzéseket készít az eddig tanultak alapján, majd belső paramétereit úgy állítja be, hogy csökkentse az előrejelzései és a tényleges adatok közötti különbséget.
- A modell ellenőrzése: Az LLM modell tanulását a validációs adatok segítségével ellenőrzik. Ez segít megnézni, hogy a modell milyen jól teljesít, és a jobb teljesítmény érdekében módosítani tudja a modell beállításait.
- A modell használata: Betanítás és értékelés után az LLM modell használatra kész. Most már integrálható alkalmazásokba vagy rendszerekbe, ahol szöveget generál a kapott új bemenetek alapján.
- A modell fejlesztése: Végül mindig van hova fejlődni. Az LLM-modell idővel tovább finomítható frissített adatok felhasználásával vagy a beállítások visszajelzések és valós használat alapján történő módosításával.
Ne feledje, ez a folyamat jelentős számítási erőforrásokat igényel, például nagy teljesítményű feldolgozóegységeket és nagy tárhelyet, valamint speciális gépi tanulási ismereteket. Ez az oka annak, hogy ezt általában elkötelezett kutatószervezetek vagy cégek végzik, amelyek hozzáféréssel rendelkeznek a szükséges infrastruktúrához és szakértelemhez.
Az LLM felügyelt vagy nem felügyelt tanulásra támaszkodik?
A nagy nyelvi modelleket általában a felügyelt tanulásnak nevezett módszerrel képezik. Leegyszerűsítve ez azt jelenti, hogy olyan példákból tanulnak, amelyek megmutatják nekik a helyes válaszokat.
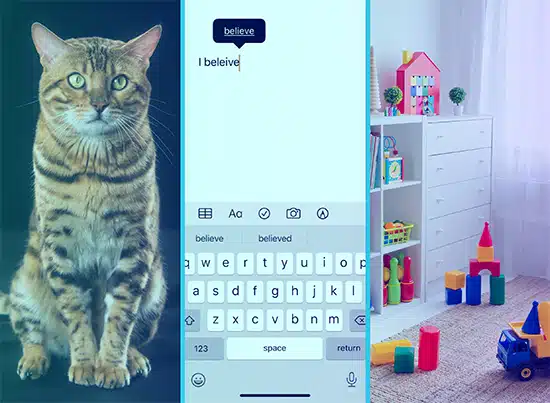 Képzeld el, hogy szavakat tanítasz egy gyereknek úgy, hogy képeket mutatsz neki. Mutatsz nekik egy képet egy macskáról, és azt mondod, hogy „macska”, és megtanulják társítani ezt a képet a szóval. Így működik a felügyelt tanulás. A modell sok szöveget (a „képeket”) és a megfelelő kimeneteket (a „szavakat”) kap, és megtanulja ezeket párosítani.
Képzeld el, hogy szavakat tanítasz egy gyereknek úgy, hogy képeket mutatsz neki. Mutatsz nekik egy képet egy macskáról, és azt mondod, hogy „macska”, és megtanulják társítani ezt a képet a szóval. Így működik a felügyelt tanulás. A modell sok szöveget (a „képeket”) és a megfelelő kimeneteket (a „szavakat”) kap, és megtanulja ezeket párosítani.
Tehát, ha egy LLM-nek betáplál egy mondatot, az megpróbálja megjósolni a következő szót vagy kifejezést a példákból tanultak alapján. Így megtanulja, hogyan lehet értelmes és a kontextushoz illeszkedő szöveget generálni.
Ennek ellenére néha az LLM-ek egy kis felügyelet nélküli tanulást is alkalmaznak. Ez olyan, mintha hagyná, hogy a gyermek felfedezze a különféle játékokkal teli szobát, és önállóan tanuljon róluk. A modell címkézetlen adatokat, tanulási mintákat és struktúrákat vizsgál anélkül, hogy megmondaná a „helyes” válaszokat.
A felügyelt tanulás bemenetekkel és kimenetekkel címkézett adatokat használ, ellentétben a felügyelt tanulással, amely nem használ felcímkézett kimeneti adatokat.
Dióhéjban az LLM-eket főként felügyelt tanulással képezik, de használhatják a felügyelet nélküli tanulást is képességeik fejlesztésére, például feltáró elemzésre és dimenziócsökkentésre.
Mekkora adatmennyiség (GB-ban) szükséges egy nagy nyelvi modell betanításához?
A beszédadat-felismerés és a hangalkalmazások lehetőségeinek világa óriási, és ezeket számos iparágban használják számos alkalmazáshoz.
Egy nagy nyelvi modell betanítása nem egy mindenki számára megfelelő folyamat, különösen, ha a szükséges adatokról van szó. Ez egy csomó dologtól függ:
- A modell kialakítása.
- Milyen munkát kell végeznie?
- A használt adatok típusa.
- Mennyire szeretnéd, hogy jól teljesítsen?
Ennek ellenére az LLM-ek képzése általában hatalmas mennyiségű szöveges adatot igényel. De milyen tömegről beszélünk? Nos, gondoljon a gigabájtokon (GB) túl. Általában terabájt (TB) vagy akár petabájt (PB) adatot vizsgálunk.
Tekintsük a GPT-3-at, az egyik legnagyobb LLM-et. Ki van képezve 570 GB szöveges adat. A kisebb LLM-eknek talán kevesebbre van szükségük – talán 10-20 GB-ra vagy akár 1 GB gigabájtra is –, de ez még mindig sok.

De ez nem csak az adatok nagyságán múlik. A minőség is számít. Az adatoknak tisztának és változatosnak kell lenniük ahhoz, hogy a modell hatékonyan tanulhasson. És nem feledkezhet meg a rejtvény egyéb kulcsfontosságú elemeiről sem, például a szükséges számítási teljesítményről, az edzéshez használt algoritmusokról és a hardverbeállításról. Mindezek a tényezők nagy szerepet játszanak az LLM képzésében.
A nagy nyelvi modellek felemelkedése: Miért fontosak?
Az LLM-ek már nem csak egy koncepció vagy egy kísérlet. Egyre fontosabb szerepet játszanak digitális környezetünkben. De miért történik ez? Mitől olyan fontosak ezek az LLM-ek? Nézzünk meg néhány kulcsfontosságú tényezőt.
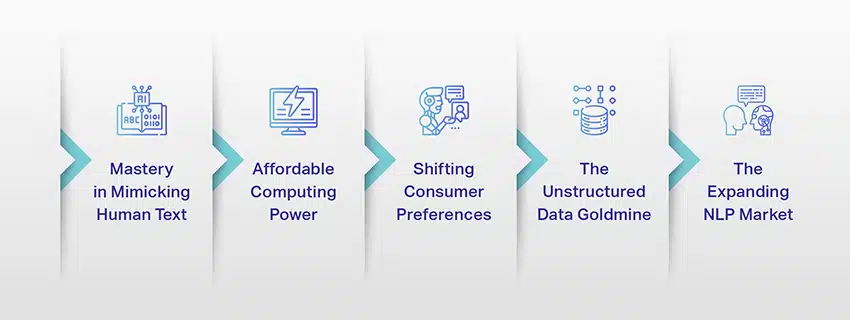
Mesterséges emberi szöveg utánzás
Az LLM-ek megváltoztatták a nyelvi alapú feladatok kezelésének módját. A robusztus gépi tanulási algoritmusok felhasználásával készült modellek képesek megérteni az emberi nyelv árnyalatait, beleértve a kontextust, az érzelmeket és bizonyos mértékig a szarkazmust is. Ez az emberi nyelv utánzási képesség nem pusztán újdonság, hanem jelentős következményekkel jár.
Az LLM-ek fejlett szöveggeneráló képességei mindent javíthatnak a tartalomkészítéstől az ügyfélszolgálati interakcióig.
Képzelje el, hogy feltehet egy digitális asszisztensnek egy összetett kérdést, és olyan választ kap, amely nemcsak értelmes, hanem koherens, releváns és társalgási hangnemben is megvan. Az LLM-ek ezt teszik lehetővé. Intuitívabb és vonzóbb ember-gép interakciót segítenek elő, gazdagítják a felhasználói élményt, és demokratizálják az információkhoz való hozzáférést.
Megfizethető számítási teljesítmény
Az LLM-ek felemelkedése nem jöhetett volna létre párhuzamos fejlesztések nélkül a számítástechnika területén. Pontosabban, a számítási erőforrások demokratizálódása jelentős szerepet játszott az LLM-ek fejlődésében és elfogadásában.
A felhőalapú platformok példátlan hozzáférést kínálnak a nagy teljesítményű számítási erőforrásokhoz. Így még kisméretű szervezetek és független kutatók is kifinomult gépi tanulási modelleket képezhetnek.
Sőt, a feldolgozó egységek (például a GPU-k és TPU-k) fejlesztései az elosztott számítástechnika térnyerésével kombinálva lehetővé tették a több milliárd paraméterrel rendelkező modellek betanítását. A számítási teljesítmény megnövekedett hozzáférhetősége lehetővé teszi az LLM-ek növekedését és sikerét, ami több innovációt és alkalmazást eredményez ezen a területen.
Fogyasztói preferenciák megváltoztatása
A fogyasztók ma nem csak válaszokat akarnak; vonzó és rokonítható interakciókra vágynak. Ahogy egyre többen nőnek fel a digitális technológia használatával, nyilvánvaló, hogy egyre növekszik az igény a természetesebbnek és emberibbnek tűnő technológia iránt. Az LLM-ek páratlan lehetőséget kínálnak ezeknek az elvárásoknak a teljesítésére. Az emberszerű szöveg generálásával ezek a modellek vonzó és dinamikus digitális élményeket hozhatnak létre, amelyek növelhetik a felhasználók elégedettségét és lojalitását. Legyen szó ügyfélszolgálatot nyújtó mesterséges intelligencia chatbotokról vagy hírfrissítésekről hangos asszisztensekről, az LLM-ek a mesterséges intelligencia egy olyan korszakát nyitják meg, amely jobban megért minket.
A strukturálatlan adatok aranybánya
A strukturálatlan adatok, például az e-mailek, a közösségi médiában közzétett bejegyzések és a vásárlói vélemények a betekintések tárházát jelentik. Becslések szerint ennek vége 80% A vállalati adatok strukturálatlanok és ütemben növekszenek 55% évente. Ezek az adatok megfelelő tőkeáttétel esetén aranybánya a vállalkozások számára.
Az LLM-ek itt jönnek szóba, mivel képesek az ilyen adatokat nagy léptékben feldolgozni és értelmezni. Olyan feladatokat tudnak kezelni, mint a hangulatelemzés, a szövegosztályozás, az információ kinyerése és még sok más, ezáltal értékes betekintést nyújtanak.
Legyen szó trendek azonosításáról közösségi médiában közzétett bejegyzésekből, vagy az ügyfelek véleményének értékeléséből, az LLM-ek segítenek a vállalkozásoknak eligazodni a nagy mennyiségű strukturálatlan adat között, és adatvezérelt döntéseket hozni.
A bővülő NLP piac
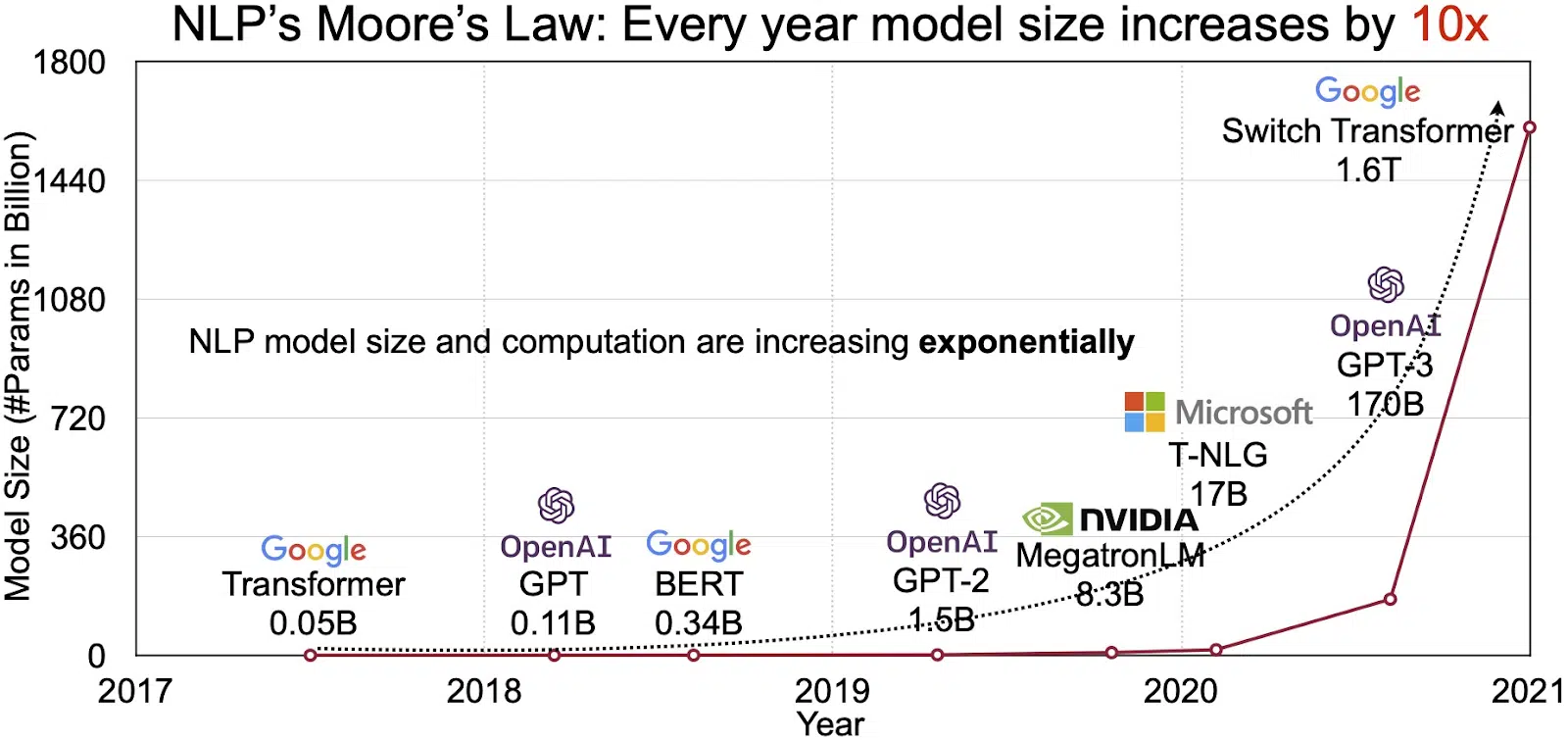
Az LLM-ekben rejlő lehetőségek a természetes nyelvi feldolgozás (NLP) gyorsan növekvő piacán tükröződnek. Elemzők előrejelzése szerint az NLP piac bővülni fog 11 milliárd dollár 2020-ban, 35-ra több mint 2026 milliárd dollár. De nem csak a piac mérete bővül. Maguk a modellek is növekednek, mind fizikai méretükben, mind a kezelt paraméterek számában. Az LLM-ek fejlődése az évek során, amint az az alábbi ábrán látható (a kép forrása: link), rámutat növekvő összetettségükre és kapacitásukra.
A nagy nyelvű modellek népszerű használati esetei
Íme néhány az LLM legnépszerűbb és legelterjedtebb felhasználási esetei:
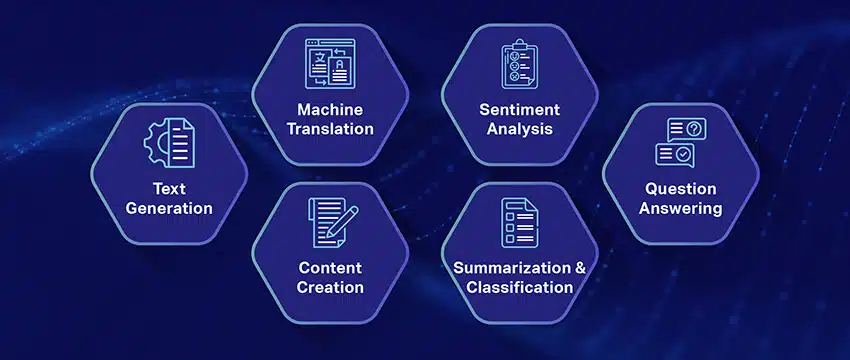
- Természetes nyelvű szöveg létrehozása: A nagy nyelvi modellek (LLM) a mesterséges intelligencia és a számítógépes nyelvészet erejét ötvözik, hogy autonóm módon állítsanak elő szövegeket természetes nyelven. Különféle felhasználói igényeket tudnak kielégíteni, például cikkeket írhatnak, dalokat készíthetnek vagy beszélgetéseket folytathatnak a felhasználókkal.
- Fordítás gépeken keresztül: Az LLM-ek hatékonyan használhatók bármilyen nyelvpár közötti szöveg fordítására. Ezek a modellek mély tanulási algoritmusokat, például visszatérő neurális hálózatokat használnak ki, hogy megértsék mind a forrás-, mind a célnyelvek nyelvi szerkezetét, ezáltal megkönnyítve a forrásszöveg lefordítását a kívánt nyelvre.
- Eredeti tartalom elkészítése: Az LLM-ek utakat nyitottak a gépek számára összefüggő és logikus tartalom létrehozására. Ez a tartalom blogbejegyzések, cikkek és más típusú tartalom létrehozására használható. A modellek mélyreható, mély tanulási tapasztalataikat kihasználva újszerű és felhasználóbarát módon formázzák és strukturálják a tartalmat.
- Érzelmek elemzése: A Large Language Models egyik érdekes alkalmazása a hangulatelemzés. Ebben a modellt arra tanítják, hogy felismerje és kategorizálja az annotált szövegben jelenlévő érzelmi állapotokat és érzéseket. A szoftver képes azonosítani az érzelmeket, például a pozitivitást, a negativitást, a semlegességet és más bonyolult érzelmeket. Ez értékes betekintést nyújthat az ügyfelek visszajelzéseibe és a különféle termékekről és szolgáltatásokról alkotott véleményébe.
- Szöveg értelmezése, összefoglalása és osztályozása: Az LLM-ek életképes struktúrát hoznak létre az AI-szoftver számára a szöveg és a szövegkörnyezet értelmezéséhez. Azáltal, hogy a modellt hatalmas mennyiségű adat megértésére és vizsgálatára utasítják, az LLM-ek lehetővé teszik az AI-modellek számára, hogy megértsék, összegezzék, sőt kategorizálják a szöveget különböző formákban és mintákban.
- Kérdések megválaszolása: A nagy nyelvi modellek a Question Answering (QA) rendszereket olyan képességgel látják el, hogy pontosan érzékeljék és válaszoljanak a felhasználó természetes nyelvű lekérdezésére. Népszerű példák erre a használati esetre: a ChatGPT és a BERT, amelyek egy lekérdezés kontextusát vizsgálják, és szövegek hatalmas gyűjteményét kutatják át, hogy releváns válaszokat adjanak a felhasználói kérdésekre.

Beszédrészes (POS) címkézés
A mondatokban szereplő szavak nyelvtani funkciójukkal vannak megjelölve, például igék, főnevek, melléknevek stb. Ez a folyamat segíti a modellt a nyelvtan és a szavak közötti kapcsolatok megértésében.

Elnevezett entitás-felismerés (NER)
A megnevezett entitások, például szervezetek, helyek és személyek egy mondaton belül meg vannak jelölve. Ez a gyakorlat segíti a modellt a szavak és kifejezések szemantikai jelentésének értelmezésében, és pontosabb válaszokat ad.

Érzelmi elemzés
A szöveges adatokhoz érzelmi címkéket rendelnek, például pozitív, semleges vagy negatív, így segít a modellnek megragadni a mondatok érzelmi felhangját. Különösen hasznos az érzelmekkel és véleményekkel kapcsolatos kérdések megválaszolásakor.
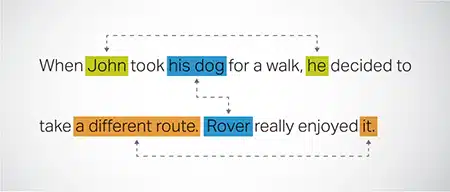
Coreference Resolution
Olyan esetek azonosítása és feloldása, amikor ugyanarra az entitásra hivatkoznak a szöveg különböző részei. Ez a lépés segít a modellnek megérteni a mondat kontextusát, így koherens válaszokhoz vezet.
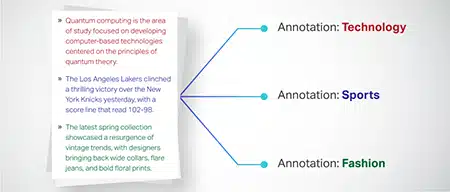
Szöveg osztályozása
A szöveges adatok előre meghatározott csoportokba vannak sorolva, például termékismertetők vagy hírcikkek. Ez segíti a modellt a szöveg műfajának vagy témájának felismerésében, és relevánsabb válaszokat generál.
Shaip ajánlata
Shaip szolgáltatások széles skáláját kínálja, hogy segítse a szervezeteket adataik kezelésében, elemzésében és a legtöbbet kihozni belőlük.
Adatok webkaparása
A Shaip által kínált egyik legfontosabb szolgáltatás az adatlekopás. Ez magában foglalja az adatok kinyerését a domain-specifikus URL-ekből. Automatizált eszközök és technikák használatával a Shaip gyorsan és hatékonyan nagy mennyiségű adatot tud lekaparni különböző webhelyekről, termékkézikönyvekből, műszaki dokumentációkból, online fórumokról, online áttekintésekről, ügyfélszolgálati adatokról, ipari szabályozási dokumentumokról stb. Ez a folyamat felbecsülhetetlen értékű lehet a vállalkozások számára, amikor releváns és konkrét adatok gyűjtése számos forrásból.

Gépi fordítás
Modelleket dolgozzon ki kiterjedt többnyelvű adatkészletek és megfelelő átírások segítségével a szöveg különböző nyelvekre történő fordításához. Ez a folyamat segít a nyelvi akadályok lebontásában és elősegíti az információk hozzáférhetőségét.
Taxonómia kivonás és létrehozás
A Shaip segíthet a taxonómia kinyerésében és létrehozásában. Ez magában foglalja az adatok osztályozását és kategorizálását egy strukturált formátumba, amely tükrözi a különböző adatpontok közötti kapcsolatokat. Ez különösen hasznos lehet a vállalkozások számára adataik rendszerezése során, így könnyebben hozzáférhetővé és könnyebben elemezhetővé válik. Például egy e-kereskedelmi vállalkozásban a termékadatokat terméktípus, márka, ár stb. alapján lehet kategorizálni, így az ügyfelek könnyebben navigálhatnak a termékkatalógusban.
Adatgyűjtés
Adatgyűjtési szolgáltatásaink kritikus, valós vagy szintetikus adatokat biztosítanak, amelyek szükségesek a generatív AI-algoritmusok betanításához, valamint a modellek pontosságának és hatékonyságának javításához. Az adatok elfogulatlanok, etikusan és felelősségteljesen származnak, szem előtt tartva az adatok védelmét és biztonságát.

Kérdés és válasz
A kérdések megválaszolása (QA) a természetes nyelvi feldolgozás egy részterülete, amely a kérdések emberi nyelven történő automatikus megválaszolására összpontosít. A minőségbiztosítási rendszerek kiterjedt szövegekre és kódokra vannak kiképezve, lehetővé téve számukra, hogy különféle típusú kérdéseket kezeljenek, beleértve a tényszerű, definíciós és véleményalapú kérdéseket. A tartományi ismeretek kulcsfontosságúak a minőségbiztosítási modellek kidolgozásához, amelyek bizonyos területekre, például ügyfélszolgálatra, egészségügyre vagy ellátási láncra vannak szabva. A generatív minőségbiztosítási megközelítések azonban lehetővé teszik a modellek számára, hogy szöveget generáljanak tartományismeret nélkül, kizárólag a kontextusra támaszkodva.
Szakértői csapatunk aprólékosan tanulmányozhatja az átfogó dokumentumokat vagy kézikönyveket, hogy kérdés-válasz párokat hozzon létre, megkönnyítve ezzel a generatív mesterséges intelligencia létrehozását a vállalkozások számára. Ez a megközelítés hatékonyan képes kezelni a felhasználói kérdéseket azáltal, hogy egy kiterjedt korpuszból bányászza ki a vonatkozó információkat. Minősített szakértőink biztosítják a csúcsminőségű kérdés-felelet párok létrehozását, amelyek különböző témákat és területeket ölelnek fel.

Szöveg Összegzés
Szakembereink képesek átfogó beszélgetések vagy hosszadalmas párbeszédek desztillálására, tömör és szemléletes összefoglalók készítésére kiterjedt szöveges adatokból.

Szöveggenerálás
Tanítson modelleket különféle stílusú szövegek széles adatkészletével, például hírcikkek, szépirodalom és költészet segítségével. Ezek a modellek aztán különféle típusú tartalmakat generálhatnak, beleértve a híreket, blogbejegyzéseket vagy közösségi média bejegyzéseket, így költséghatékony és időtakarékos megoldást kínálnak a tartalomkészítéshez.
Speech Recognition
A beszélt nyelv megértésére képes modellek kidolgozása különféle alkalmazásokhoz. Ez magában foglalja a hanggal aktiválható asszisztenseket, a diktálószoftvert és a valós idejű fordítóeszközöket. A folyamat magában foglalja egy átfogó adatkészlet felhasználását, amely a beszélt nyelv hangfelvételeiből áll, párosítva a megfelelő átiratokkal.

Termékjavaslatok
A vásárlók vásárlási előzményeinek kiterjedt adatkészleteinek felhasználásával dolgozzon ki modelleket, beleértve azokat a címkéket is, amelyek rámutatnak arra, hogy a vásárlók milyen termékeket szeretnének megvásárolni. A cél az, hogy precíz javaslatokat adjunk az ügyfeleknek, ezáltal növeljük az értékesítést és növeljük a vevői elégedettséget.
Képfelirat
Forradalmasítsa képértelmezési folyamatát a legmodernebb, mesterséges intelligencia által vezérelt képfeliratozási szolgáltatásunkkal. Vitalitást öntünk a képekbe azáltal, hogy pontos és kontextuálisan értelmes leírásokat készítünk. Ez megnyitja az utat az innovatív elköteleződés és interakciós lehetőségek előtt a vizuális tartalommal a közönség számára.

Szövegfelolvasó szolgáltatások képzése
Az emberi beszéd hangfelvételeiből álló kiterjedt adatkészletet kínálunk, amely ideális az AI-modellek betanításához. Ezek a modellek képesek természetes és vonzó hangokat generálni az alkalmazásokhoz, így egyedi és magával ragadó hangélményt biztosítanak a felhasználók számára.



