




Az egészségügy megerősítése generatív mesterséges intelligencia segítségével: Forradalmasítja a diagnózist és a kezelést
Az elmúlt években a mesterséges intelligencia (AI) jelentős előrelépéseket tett a különböző iparágakban, és ez alól az egészségügy sem kivétel. Generatív AI, a mesterséges intelligencia egy részhalmaza
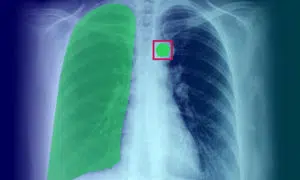
Orvosi képfeljegyzés: meghatározás, alkalmazás, felhasználási esetek és típusok
Az orvosi képannotáció létfontosságú szerepet játszik a gépi tanulási algoritmusok és mesterséges intelligencia modellek számára a szükséges képzési adatokkal való ellátásában. Ez a folyamat elengedhetetlen ahhoz

Etika és elfogultság: Eligazodás az emberi és mesterséges intelligencia együttműködésének kihívásai között a modellértékelésben
A mesterséges intelligencia (AI) átalakító erejének hasznosítása érdekében a technológiai közösség kritikus kihívással néz szembe: az etikai integritás biztosítása és az elfogultság minimalizálása

Az emberi érintés: A mesterséges intelligencia kreativitásának fokozása szubjektív értékeléssel
A mesterséges intelligencia (AI) gyorsan fejlődő világában a kreativitásra való törekvés már nem csupán emberi erőfeszítés. A mai mesterséges intelligencia technológiái tönkremennek

A keresési relevancia maximalizálása adatcímkézéssel: tippek és bevált módszerek
A felhasználók manapság hatalmas mennyiségű információban vannak elmerülve, ami bonyolulttá teszi a szükséges információk megtalálását. A keresési relevancia az információk pontosságát méri

A szakadék áthidalása: Az emberi intuíció integrálása az AI-modell értékelésébe
Bevezetés Egy olyan korszakban, ahol a mesterséges intelligencia (AI) életünk minden oldalát alakítja, az emberi intuíció integrálása a mesterséges intelligencia modellek értékelésébe

A legjobb nyílt forráskódú egészségügyi adatkészletek gépi tanulási projektekhez
A globális egészségügyi rendszer napi szinten hatalmas mennyiségű orvosi adatot állít elő, amelyet gépi tanulási alkalmazásokhoz lehet hasznosítani.

Navigálás az adatok védelmében az AI-ban: Megfelelőségi és innovációs stratégiák
Bevezetés A mesterséges intelligencia (AI) gyorsan fejlődő terepén az olyan vállalatok, mint az OpenAI, jelentős kihívásokkal néznek szembe az adatok iránti kielégíthetetlen igény és szigorú egyensúly megteremtésében.
Az adatok jövője az intelligens karakterfelismeréssel (ICR)
A kézzel írott jegyzeteknek még digitális világunkban is különleges varázsa van. Az intelligens karakterfelismerés (ICR) segít áthidalni az analóg és a digitális szakadékot, átalakítja a kézzel írt szöveget

Az NLP hatása az egészségügyi diagnosztikára
A Natural Language Processing (NLP) átalakítja a technológiával való interakciónkat. Feldolgozza az emberi nyelvet, hogy feltárja a hatalmas információs potenciált. A technológia ugyanazt a lehetőséget rejti magában

A megfelelő beszédfelismerési adatkészlet kiválasztása az AI-modellhez
Képzelje el, hogy Sirivel vagy Alexával kommunikál. Lenyűgöző az a képességük, hogy megértsék beszédünket. Ez a képesség a képzésük során használt adatkészletekből fakad. Ezek

Egészségügyi adatkészletek: Boon for Healthcare AI
A mesterséges intelligencia, amelyet korábban leginkább a tudományos-fantasztikus irodalomban találtak, ma már valósággá vált, amely különféle iparágak növekedését táplálja. Következő lépés stratégiai tanácsadás

Tanulás megerősítése emberi visszajelzéssel: meghatározás és lépések
A megerősítési tanulás (RL) a gépi tanulás egyik fajtája. Ebben a megközelítésben az algoritmusok megpróbálnak és hibázva tanulnak meg döntéseket hozni, hasonlóan az emberekhez.

A mesterséges intelligencia hallucinációinak okai (és azok csökkentésére szolgáló technikák)
A mesterséges intelligencia hallucinációi azokra az esetekre utalnak, amikor az AI-modellek, különösen a nagy nyelvi modellek (LLM-ek) igaznak látszó, de helytelen vagy a

Mi az a klinikai validálás? Útmutató a bevált gyakorlatokhoz és folyamatokhoz
Gondoljon egy olyan forgatókönyvre, amelyben új diagnosztikai eszközt fejlesztenek ki. Az orvosok izgatottak a benne rejlő lehetőségek miatt. Mégis, mielőtt beépítenék a rutinellátásba, ők

Az etikus mesterséges intelligencia jelentősége / A méltányos mesterségesintelligencia és az elkerülendő torzítások típusai
A mesterséges intelligencia (AI) virágzó területén az etikai megfontolások és a méltányosság előtérbe helyezése több, mint erkölcsi kényszer – ez alapvető szükséglet a

AI orvosi feljegyzések összefoglalása: meghatározások, kihívások és legjobb gyakorlatok
Az egészségügyi feljegyzések számának növekedése az egészségügyi ágazatban egyszerre jelent kihívást és lehetőséget. Képzelj el egy világot, ahol minden részlet a

Klinikai adatok absztrakciója: meghatározás, folyamat és még sok más
A kórházak és klinikák évente több ezer beteggel találkoznak. Ehhez nagyszámú elhivatott orvosra és nővérre van szükség. Fáradhatatlanul dolgoznak az ellátásért

Szintetikus adatok az egészségügyben: meghatározások, előnyök és kihívások
Képzeljünk el egy forgatókönyvet, amikor a kutatók új gyógyszert fejlesztenek. Kiterjedt betegadatokra van szükségük a teszteléshez, de jelentős aggályok merülnek fel a magánélet és a

HIPAA szakértői meghatározás az azonosítás megszüntetésére
Az egészségbiztosítási hordozhatóságról és elszámoltathatóságról szóló törvény (HIPAA) meghatározza a betegek adatainak védelmét az egészségügyi ellátásban. Ennek egyik döntő aspektusa a Protected azonosításának megszüntetése

Úttörő onkológiai kutatás az NLP segítségével: A Shaip áttörése
Esettanulmány letöltése A rák leküzdésére irányuló törekvésben az adatok ugyanolyan létfontosságúak, mint az elszántság. A Shaipnél büszkék vagyunk arra, hogy jelentős ugrást tettünk lehetővé
A természetes nyelvi feldolgozás (NLP) ereje a radiológiában: a diagnózis és a hatékonyság javítása
A radiológia döntő szerepet játszik az egészségügyben. Képalkotó technikákat, például CT-vizsgálatot, röntgensugarat és MRI-t használ a különféle állapotok diagnosztizálására és kezelésére. Természetes nyelv

A természetes nyelvi feldolgozás (NLP) szerepe az onkológiában
A rák világszerte jelentős egészségügyi kihívást jelent. Ez akkor fordul elő, amikor a sejtek ellenőrizetlen módon növekednek és terjednek. Ez a második vezető halálok

Minden, amit tudnod kell az erősítésről Az emberi visszajelzésekből való tanulás
2023-ban hatalmas növekedés következett be az olyan mesterséges intelligencia-eszközök, mint a ChatGPT, elterjedése. Ez a hullám élénk vitát indított el, és az emberek az AI előnyeiről vitatkoznak,

Az AI ereje az autóiparban
Ami az AI autókba való integrálását illeti, a világ figyelemre méltó válaszút előtt áll. Képzelje el, hogy egy forgalmas úton vezet mesterséges intelligencia segítségével, és kezeli a sajátját

A szövegfelolvasó előnyei az iparágakban
A text-to-speech (TTS) technológia egy innovatív megoldás, amely az írott szöveget beszélt szavakká alakítja. Számos iparágban megváltoztatta a játékot, és forradalmasította

Az A – Z adatmegjegyzés
Útmutató kezdőknek az adatfeliratozáshoz: tippek és bevált gyakorlatok Az Ultimate Buyers Guide 2024 Index táblázata Bevezetés Mi az a gépi tanulás? Mi a

Útmutató az adatok azonosításához: Minden, amit egy kezdőnek tudnia kell (2024-ben)
A digitális átalakulás korában az egészségügyi szervezetek gyorsan áthelyezik működésüket digitális platformokra. Miközben ez hatékonyságot és egyszerűsített folyamatokat eredményez, egyben

Generatív mesterséges intelligencia az egészségügyben: alkalmazások, előnyök, kihívások és jövőbeli trendek
Az egészségügy mindig is olyan terület volt, ahol az innovációt nagyra értékelik, és ez kulcsfontosságú az életek megmentésében. A technológiai fejlődés ellenére az egészségügyi ágazat továbbra is elhúzódó kihívásokkal néz szembe.

Különbség a felelős AI és az etikus AI között
A gyorsan növekvő globális mesterséges intelligencia piac 1847-ban várhatóan eléri az 2030 milliárd dollárt. Mivel a mesterséges intelligencia életünk középpontjában áll, tudjuk, hogy milyen



















Az egészségügy megerősítése generatív mesterséges intelligencia segítségével: Forradalmasítja a diagnózist és a kezelést
Az elmúlt években a mesterséges intelligencia (AI) jelentős előrelépéseket tett a különböző iparágakban, és ez alól az egészségügy sem kivétel. Generatív AI, a mesterséges intelligencia egy részhalmaza
Orvosi képfeljegyzés: meghatározás, alkalmazás, felhasználási esetek és típusok
Az orvosi képannotáció létfontosságú szerepet játszik a gépi tanulási algoritmusok és mesterséges intelligencia modellek számára a szükséges képzési adatokkal való ellátásában. Ez a folyamat elengedhetetlen ahhoz
Etika és elfogultság: Eligazodás az emberi és mesterséges intelligencia együttműködésének kihívásai között a modellértékelésben
A mesterséges intelligencia (AI) átalakító erejének hasznosítása érdekében a technológiai közösség kritikus kihívással néz szembe: az etikai integritás biztosítása és az elfogultság minimalizálása
Az emberi érintés: A mesterséges intelligencia kreativitásának fokozása szubjektív értékeléssel
A mesterséges intelligencia (AI) gyorsan fejlődő világában a kreativitásra való törekvés már nem csupán emberi erőfeszítés. A mai mesterséges intelligencia technológiái tönkremennek
A keresési relevancia maximalizálása adatcímkézéssel: tippek és bevált módszerek
A felhasználók manapság hatalmas mennyiségű információban vannak elmerülve, ami bonyolulttá teszi a szükséges információk megtalálását. A keresési relevancia az információk pontosságát méri
A szakadék áthidalása: Az emberi intuíció integrálása az AI-modell értékelésébe
Bevezetés Egy olyan korszakban, ahol a mesterséges intelligencia (AI) életünk minden oldalát alakítja, az emberi intuíció integrálása a mesterséges intelligencia modellek értékelésébe
A legjobb nyílt forráskódú egészségügyi adatkészletek gépi tanulási projektekhez
A globális egészségügyi rendszer napi szinten hatalmas mennyiségű orvosi adatot állít elő, amelyet gépi tanulási alkalmazásokhoz lehet hasznosítani.
Navigálás az adatok védelmében az AI-ban: Megfelelőségi és innovációs stratégiák
Bevezetés A mesterséges intelligencia (AI) gyorsan fejlődő terepén az olyan vállalatok, mint az OpenAI, jelentős kihívásokkal néznek szembe az adatok iránti kielégíthetetlen igény és szigorú egyensúly megteremtésében.
Az adatok jövője az intelligens karakterfelismeréssel (ICR)
A kézzel írott jegyzeteknek még digitális világunkban is különleges varázsa van. Az intelligens karakterfelismerés (ICR) segít áthidalni az analóg és a digitális szakadékot, átalakítja a kézzel írt szöveget
Az NLP hatása az egészségügyi diagnosztikára
A Natural Language Processing (NLP) átalakítja a technológiával való interakciónkat. Feldolgozza az emberi nyelvet, hogy feltárja a hatalmas információs potenciált. A technológia ugyanazt a lehetőséget rejti magában
A megfelelő beszédfelismerési adatkészlet kiválasztása az AI-modellhez
Képzelje el, hogy Sirivel vagy Alexával kommunikál. Lenyűgöző az a képességük, hogy megértsék beszédünket. Ez a képesség a képzésük során használt adatkészletekből fakad. Ezek
Egészségügyi adatkészletek: Boon for Healthcare AI
A mesterséges intelligencia, amelyet korábban leginkább a tudományos-fantasztikus irodalomban találtak, ma már valósággá vált, amely különféle iparágak növekedését táplálja. Következő lépés stratégiai tanácsadás
Tanulás megerősítése emberi visszajelzéssel: meghatározás és lépések
A megerősítési tanulás (RL) a gépi tanulás egyik fajtája. Ebben a megközelítésben az algoritmusok megpróbálnak és hibázva tanulnak meg döntéseket hozni, hasonlóan az emberekhez.
A mesterséges intelligencia hallucinációinak okai (és azok csökkentésére szolgáló technikák)
A mesterséges intelligencia hallucinációi azokra az esetekre utalnak, amikor az AI-modellek, különösen a nagy nyelvi modellek (LLM-ek) igaznak látszó, de helytelen vagy a
Mi az a klinikai validálás? Útmutató a bevált gyakorlatokhoz és folyamatokhoz
Gondoljon egy olyan forgatókönyvre, amelyben új diagnosztikai eszközt fejlesztenek ki. Az orvosok izgatottak a benne rejlő lehetőségek miatt. Mégis, mielőtt beépítenék a rutinellátásba, ők
Az etikus mesterséges intelligencia jelentősége / A méltányos mesterségesintelligencia és az elkerülendő torzítások típusai
A mesterséges intelligencia (AI) virágzó területén az etikai megfontolások és a méltányosság előtérbe helyezése több, mint erkölcsi kényszer – ez alapvető szükséglet a
AI orvosi feljegyzések összefoglalása: meghatározások, kihívások és legjobb gyakorlatok
Az egészségügyi feljegyzések számának növekedése az egészségügyi ágazatban egyszerre jelent kihívást és lehetőséget. Képzelj el egy világot, ahol minden részlet a
Klinikai adatok absztrakciója: meghatározás, folyamat és még sok más
A kórházak és klinikák évente több ezer beteggel találkoznak. Ehhez nagyszámú elhivatott orvosra és nővérre van szükség. Fáradhatatlanul dolgoznak az ellátásért
Szintetikus adatok az egészségügyben: meghatározások, előnyök és kihívások
Képzeljünk el egy forgatókönyvet, amikor a kutatók új gyógyszert fejlesztenek. Kiterjedt betegadatokra van szükségük a teszteléshez, de jelentős aggályok merülnek fel a magánélet és a
HIPAA szakértői meghatározás az azonosítás megszüntetésére
Az egészségbiztosítási hordozhatóságról és elszámoltathatóságról szóló törvény (HIPAA) meghatározza a betegek adatainak védelmét az egészségügyi ellátásban. Ennek egyik döntő aspektusa a Protected azonosításának megszüntetése
Úttörő onkológiai kutatás az NLP segítségével: A Shaip áttörése
Esettanulmány letöltése A rák leküzdésére irányuló törekvésben az adatok ugyanolyan létfontosságúak, mint az elszántság. A Shaipnél büszkék vagyunk arra, hogy jelentős ugrást tettünk lehetővé
A természetes nyelvi feldolgozás (NLP) ereje a radiológiában: a diagnózis és a hatékonyság javítása
A radiológia döntő szerepet játszik az egészségügyben. Képalkotó technikákat, például CT-vizsgálatot, röntgensugarat és MRI-t használ a különféle állapotok diagnosztizálására és kezelésére. Természetes nyelv
A természetes nyelvi feldolgozás (NLP) szerepe az onkológiában
A rák világszerte jelentős egészségügyi kihívást jelent. Ez akkor fordul elő, amikor a sejtek ellenőrizetlen módon növekednek és terjednek. Ez a második vezető halálok
Minden, amit tudnod kell az erősítésről Az emberi visszajelzésekből való tanulás
2023-ban hatalmas növekedés következett be az olyan mesterséges intelligencia-eszközök, mint a ChatGPT, elterjedése. Ez a hullám élénk vitát indított el, és az emberek az AI előnyeiről vitatkoznak,
Az AI ereje az autóiparban
Ami az AI autókba való integrálását illeti, a világ figyelemre méltó válaszút előtt áll. Képzelje el, hogy egy forgalmas úton vezet mesterséges intelligencia segítségével, és kezeli a sajátját
A szövegfelolvasó előnyei az iparágakban
A text-to-speech (TTS) technológia egy innovatív megoldás, amely az írott szöveget beszélt szavakká alakítja. Számos iparágban megváltoztatta a játékot, és forradalmasította
Az A – Z adatmegjegyzés
Útmutató kezdőknek az adatfeliratozáshoz: tippek és bevált gyakorlatok Az Ultimate Buyers Guide 2024 Index táblázata Bevezetés Mi az a gépi tanulás? Mi a
Útmutató az adatok azonosításához: Minden, amit egy kezdőnek tudnia kell (2024-ben)
A digitális átalakulás korában az egészségügyi szervezetek gyorsan áthelyezik működésüket digitális platformokra. Miközben ez hatékonyságot és egyszerűsített folyamatokat eredményez, egyben
Generatív mesterséges intelligencia az egészségügyben: alkalmazások, előnyök, kihívások és jövőbeli trendek
Az egészségügy mindig is olyan terület volt, ahol az innovációt nagyra értékelik, és ez kulcsfontosságú az életek megmentésében. A technológiai fejlődés ellenére az egészségügyi ágazat továbbra is elhúzódó kihívásokkal néz szembe.
Különbség a felelős AI és az etikus AI között
A gyorsan növekvő globális mesterséges intelligencia piac 1847-ban várhatóan eléri az 2030 milliárd dollárt. Mivel a mesterséges intelligencia életünk középpontjában áll, tudjuk, hogy milyen

Mi az NLP? Hogyan működik, előnyei, kihívásai, példák
Infografika letöltése Mi az NLP? A Natural Language Processing (NLP) a mesterséges intelligencia (AI) egyik részterülete. Lehetővé teszi a robotok számára az emberi nyelv elemzését és megértését,

OCR – Definíció, előnyök, kihívások és használati esetek [Infographic]
Az OCR egy olyan technológia, amely lehetővé teszi a gépek számára nyomtatott szövegek és képek olvasását. Gyakran használják üzleti alkalmazásokban, például dokumentumok tárolására vagy feldolgozásra történő digitalizálására, valamint fogyasztói alkalmazásokban, például költségtérítési bizonylatok szkennelésére.

A társalgási AI állapota 2022
A Konverzionális AI állapota 2022 Mi a Konverzionális AI? Programozott és intelligens módja a beszélgetési élmény biztosításának, beszélgetés valós emberekkel, digitális és telekommunikációs eszközökkel

Mi az adatgyűjtés? Minden, amit egy kezdőnek tudnia kell
Intelligens #AI/ #ML modellek mindenhol megtalálhatók, legyen szó prediktív egészségügyi modellekről, proaktív diagnózisról,

Mi az adatcímkézés? Minden, amit egy kezdőnek tudnia kell
Infografika letöltése Az intelligens AI -modelleket alaposan ki kell képezni, hogy képesek legyenek azonosítani a mintákat, objektumokat és végül megbízható döntéseket hozni. Azonban a képzett