Bevezetés
 A mesterséges intelligencia arról szól, hogy gépeket használnak az emberek életének és életmódjának felemelésére azáltal, hogy érdekessé és leegyszerűsítik hétköznapi életüket. Az AI-nak soha nem kellene uralkodónak lennie, hanem kiegészítőnek, amely az emberekkel együtt dolgozik, hogy megoldja a valószínűtlen dolgokat, és előkészítse az utat a kollektív evolúció előtt.
A mesterséges intelligencia arról szól, hogy gépeket használnak az emberek életének és életmódjának felemelésére azáltal, hogy érdekessé és leegyszerűsítik hétköznapi életüket. Az AI-nak soha nem kellene uralkodónak lennie, hanem kiegészítőnek, amely az emberekkel együtt dolgozik, hogy megoldja a valószínűtlen dolgokat, és előkészítse az utat a kollektív evolúció előtt.
Jelenleg a helyes úton haladunk, és az AI segítségével jelentős áttörések történtek az iparágakban. Ha például az egészségügyet vesszük, akkor a gépi tanulási modellekkel kísért mesterséges intelligencia rendszerek segítenek a szakértőknek abban, hogy jobban megértsék a rákot, és kezelési módszereket találjanak ki rá. A neurológiai rendellenességeket és aggodalmakat, például a PTSD-t, az AI segítségével kezelik. Az MI-alapú klinikai vizsgálatoknak és szimulációknak köszönhetően gyors ütemben fejlesztik a vakcinákat.
Nem csak az egészségügy, minden iparág vagy szegmens, amelyet az AI érint, forradalmasítás alatt áll. Az autonóm járművek, az intelligens kisboltok, a viselhető eszközök, mint a FitBit és még az okostelefonok kamerái is képesek jobb képeket készíteni arcunkról mesterséges intelligencia segítségével.
Az AI-térben zajló újításoknak köszönhetően a vállalatok különféle felhasználási esetekkel és megoldásokkal szállnak be a spektrumba. Emiatt a globális mesterségesintelligencia-piac várhatóan 267 végére eléri a 2027 milliárd dolláros piaci értéket. Emellett a vállalkozások mintegy 37%-a már most is alkalmaz mesterségesintelligencia-megoldásokat folyamataiba és termékeibe.
Még érdekesebb, hogy a ma használt termékek és szolgáltatások közel 77%-át mesterséges intelligencia működteti. Miközben a technológiai koncepció jelentősen terjed a vertikálisok között, hogyan tudnak a vállalkozások lehetetlent tenni az AI-val?

 Hogyan jósolják meg pontosan az olyan egyszerű eszközök, mint az óra, az emberek szívrohamát? Hogyan lehetséges, hogy azok az autók és autók, amelyekben mindig is kellett sofőr, hirtelen kevesebbet vezetnek az utakon?
Hogyan jósolják meg pontosan az olyan egyszerű eszközök, mint az óra, az emberek szívrohamát? Hogyan lehetséges, hogy azok az autók és autók, amelyekben mindig is kellett sofőr, hirtelen kevesebbet vezetnek az utakon?
Hogyan hitetik el velünk a chatbotok, hogy egy másik emberrel beszélünk a másik oldalon?
Ha minden kérdésre megfigyeli a választ, az egyetlen elemre csapódik le – az ADATOKRA. Az adatok az összes mesterséges intelligencia-specifikus művelet és folyamat középpontjában állnak. Ezek az adatok segítenek a gépeknek megérteni a fogalmakat, feldolgozni a bemeneteket és pontos eredményeket szolgáltatni.
Az összes rendelkezésre álló fő mesterséges intelligencia-megoldás egy olyan kulcsfontosságú folyamat terméke, amelyet adatgyűjtésnek vagy adatgyűjtésnek vagy mesterséges intelligencia képzési adatoknak nevezünk.
Ez a kiterjedt útmutató arról szól, hogy segítsen megérteni, mi ez, és miért fontos.
Mi az AI adatgyűjtés?
A gépeknek nincs saját eszük. Ennek az elvont fogalomnak a hiánya nélkülözi azokat a véleményeket, tényeket és képességeket, mint az érvelés, a megismerés és egyebek. Ezek csak mozdíthatatlan dobozok vagy eszközök, amelyek helyet foglalnak el. Ahhoz, hogy ezeket hatékony médiumokká alakítsa, algoritmusokra és még fontosabb adatokra van szüksége.
 A kifejlesztett algoritmusoknak szüksége van valamire, amin dolgozni és feldolgozni kell, és ez a valami releváns, kontextuális és friss adat. Az ilyen adatok gyűjtésének folyamatát a gépek számára a szándékolt célok teljesítése érdekében AI adatgyűjtésnek nevezik.
A kifejlesztett algoritmusoknak szüksége van valamire, amin dolgozni és feldolgozni kell, és ez a valami releváns, kontextuális és friss adat. Az ilyen adatok gyűjtésének folyamatát a gépek számára a szándékolt célok teljesítése érdekében AI adatgyűjtésnek nevezik.
Minden egyes mesterséges intelligencia-kompatibilis termék vagy megoldás, amelyet ma használunk, és az általuk kínált eredmények több éves képzés, fejlesztés és optimalizálás eredménye. A navigációs útvonalakat kínáló eszközöktől az olyan összetett rendszerekig, amelyek napokkal előre megjósolják a berendezés meghibásodását, minden egyes entitás évekig tartó mesterséges intelligencia képzésen ment keresztül, hogy pontos eredményeket tudjon nyújtani.
AI adatgyűjtés A mesterséges intelligencia fejlesztési folyamatának elõzetes lépése, amely már a kezdetektõl meghatározza, hogy egy AI-rendszer mennyire hatékony és eredményes. A releváns adatkészletek számtalan forrásból való beszerzésének folyamata segíti az AI-modelleket abban, hogy jobban feldolgozzák a részleteket, és értelmes eredményeket érjenek el.




Hogyan gyűjtsünk adatokat egy gépi tanuláshoz?
 Itt kezdenek kicsit bonyolulttá válni a dolgok. Kezdettől fogva úgy tűnt, hogy egy valós problémára van megoldás a fejedben, tudod, hogy a mesterséges intelligencia lenne az ideális megoldás, és már kifejlesztetted a modelleidet. Most azonban a döntő szakaszban van, amikor el kell kezdenie a mesterséges intelligencia képzési folyamatait. Bőséges mesterséges intelligencia képzési adatra van szüksége ahhoz, hogy modelljei megtanulják a fogalmakat és eredményeket érjenek el. Az eredmények teszteléséhez és az algoritmusok optimalizálásához érvényesítési adatokra is szükség van.
Itt kezdenek kicsit bonyolulttá válni a dolgok. Kezdettől fogva úgy tűnt, hogy egy valós problémára van megoldás a fejedben, tudod, hogy a mesterséges intelligencia lenne az ideális megoldás, és már kifejlesztetted a modelleidet. Most azonban a döntő szakaszban van, amikor el kell kezdenie a mesterséges intelligencia képzési folyamatait. Bőséges mesterséges intelligencia képzési adatra van szüksége ahhoz, hogy modelljei megtanulják a fogalmakat és eredményeket érjenek el. Az eredmények teszteléséhez és az algoritmusok optimalizálásához érvényesítési adatokra is szükség van.
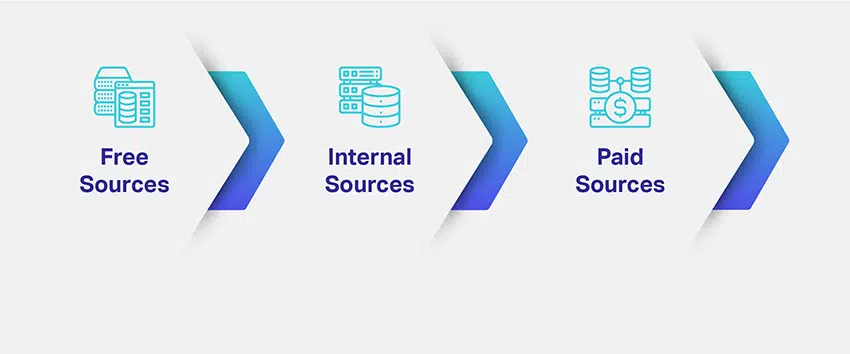
Szóval, honnan szerzi be adatait? Milyen adatokra van szüksége és mennyi? Milyen több forrásból lehet lekérni a releváns adatokat?
A vállalatok felmérik ML modelljeik rést és célját, és felvázolják a releváns adatkészletek forrásának lehetséges módjait. A szükséges adattípus meghatározása megoldja az adatbeszerzéssel kapcsolatos aggodalmak nagy részét. A jobb kép érdekében az adatgyűjtéshez különböző csatornák, utak, források vagy médiumok állnak rendelkezésre:
Hogyan befolyásolják a rossz adatok a mesterséges intelligencia ambícióit?
Azért soroltuk fel a három leggyakoribb adatforrást, hogy legyen elképzelése az adatgyűjtésről és -beszerzésről. Ezen a ponton azonban elengedhetetlen annak megértése, hogy az Ön döntése változatlanul eldöntheti az AI-megoldás sorsát.
Hasonlóan ahhoz, hogy a kiváló minőségű mesterséges intelligencia képzési adatok segítségével a modell pontos és időszerű eredményeket érhet el, a rossz képzési adatok is tönkretehetik az AI-modelleket, torzíthatják az eredményeket, torzítást okozhatnak, és egyéb nemkívánatos következményekkel járhatnak.
De miért történik ez? Nem kellene semmilyen adatnak tanítania és optimalizálnia az AI-modelljét? Őszintén szólva nem. Értsük meg ezt tovább.
Rossz adatok – mi ez?
 Rossz adat minden olyan adat, amely irreleváns, helytelen, hiányos vagy elfogult. A rosszul definiált adatgyűjtési stratégiáknak köszönhetően a legtöbb adattudós és annotációs szakértők kénytelenek rossz adatokon dolgozni.
Rossz adat minden olyan adat, amely irreleváns, helytelen, hiányos vagy elfogult. A rosszul definiált adatgyűjtési stratégiáknak köszönhetően a legtöbb adattudós és annotációs szakértők kénytelenek rossz adatokon dolgozni.
A különbség a strukturálatlan és a rossz adatok között az, hogy a strukturálatlan adatokba mindenütt betekintést nyerhetünk. De lényegében ettől függetlenül hasznosak lehetnek. További idő eltöltésével az adatkutatók továbbra is képesek lennének releváns információkat kinyerni strukturálatlan adatkészletekből. A rossz adatok esetében azonban nem ez a helyzet. Ezek az adatkészletek nem vagy csak korlátozott mértékben tartalmaznak olyan betekintést vagy információt, amely értékes vagy releváns az AI-projektje vagy annak képzési céljai szempontjából.
Tehát ha az adatkészleteket ingyenes forrásokból szerzi be, vagy lazán kialakított belső adatkapcsolati pontokkal rendelkezik, nagy a valószínűsége annak, hogy rossz adatokat tölt le vagy generál. Amikor a tudósok rossz adatokon dolgoznak, Ön nemcsak emberi órákat veszít, hanem a terméke piacra dobását is szorgalmazza.
Ha még mindig nem világos, hogy a rossz adatok milyen hatással lehetnek ambícióira, íme egy gyors lista:
- Számtalan órát tölt a rossz adatok beszerzésével, és órákat, erőfeszítéseket és pénzt pazarol erőforrásokra.
- A rossz adatok jogi problémákat okozhatnak, ha nem veszik észre, és csökkenthetik a mesterséges intelligencia hatékonyságát
modellek. - Ha a rossz adatokra kiképzett terméket élőben viszi át, az befolyásolja a felhasználói élményt
- A rossz adatok torzíthatják az eredményeket és a következtetéseket, ami további visszahatásokat okozhat.
Tehát, ha arra kíváncsi, hogy van-e megoldás erre, akkor valójában van.
AI képzési adatszolgáltatók a mentésben
 Az egyik alapvető megoldás az adatszolgáltató (fizetős források) választása. A mesterséges intelligencia képzési adatszolgáltatói gondoskodnak arról, hogy az Ön által kapott adatok pontosak és relevánsak legyenek, és az adatkészleteket strukturált formában kézbesítik. Nem kell részt vennie a portálról portálra való áttéréssel járó gondokba az adatkészletek keresése során.
Az egyik alapvető megoldás az adatszolgáltató (fizetős források) választása. A mesterséges intelligencia képzési adatszolgáltatói gondoskodnak arról, hogy az Ön által kapott adatok pontosak és relevánsak legyenek, és az adatkészleteket strukturált formában kézbesítik. Nem kell részt vennie a portálról portálra való áttéréssel járó gondokba az adatkészletek keresése során.
Mindössze annyit kell tennie, hogy felveszi az adatokat, és tökéletesre tanítja mesterségesintelligencia-modelljeit. Ennek ellenére biztosak vagyunk benne, hogy a következő kérdése az adatszolgáltatókkal való együttműködés költségeire vonatkozik. Megértjük, hogy néhányan már dolgoznak a mentális költségvetésen, és mi is pontosan errefelé tartunk a következőn.
Tényezők, amelyeket figyelembe kell venni az adatgyűjtési projekt hatékony költségvetésének kidolgozásakor
Az AI-képzés szisztematikus megközelítés, ezért a költségvetés-tervezés ennek szerves részévé válik. Az olyan tényezőket, mint a megtérülés, az eredmények pontossága, a képzési módszerek és egyebek figyelembe kell venni, mielőtt hatalmas összeget fektetnénk be az AI fejlesztésébe. Ebben a szakaszban sok projektmenedzser vagy cégtulajdonos tapogatózik. Elhamarkodott döntéseket hoznak, amelyek visszafordíthatatlan változásokat hoznak a termékfejlesztési folyamatukban, és végül több kiadásra kényszerítik őket.
Ez a rész azonban megfelelő betekintést nyújt Önnek. Amikor leülsz dolgozni az AI-képzés költségvetésén, három dolog vagy tényező elkerülhetetlen.

Nézzük mindegyiket részletesen.
A szükséges adatmennyiség
Mindvégig azt mondtuk, hogy az AI-modell hatékonysága és pontossága attól függ, hogy mennyire képzett. Ez azt jelenti, hogy minél nagyobb az adatkészletek mennyisége, annál több a tanulás. De ez nagyon homályos. A Dimensional Research közzétett egy jelentést, amelyből kiderült, hogy a vállalkozásoknak legalább 100,000 XNUMX mintaadatkészletre van szükségük a mesterséges intelligencia modellek képzéséhez.
100,000 100,000 adatkészlet alatt XNUMX XNUMX minőségi és releváns adatkészletet értünk. Ezeknek az adatkészleteknek rendelkezniük kell az algoritmusokhoz és a gépi tanulási modellekhez szükséges összes alapvető attribútummal, megjegyzéssel és betekintéssel az információk feldolgozásához és a tervezett feladatok végrehajtásához.
Mivel ez egy általános ökölszabály, értsük meg jobban, hogy a szükséges adatok mennyisége egy másik bonyolult tényezőtől is függ, amely az Ön vállalkozása használati esete. Azt is meghatározza, hogy mit szándékozik tenni a termékével vagy megoldásával, hogy mennyi adatra van szüksége. Például egy ajánlómotort építő vállalkozásnak más adatmennyiségi követelményei vannak, mint egy chatbotot építő cégnek.
Adatárazási stratégia
Ha végzett a ténylegesen szükséges adatmennyiség véglegesítésével, legközelebb egy adatárazási stratégián kell dolgoznia. Ez leegyszerűsítve azt jelenti, hogyan fizetne a beszerzett vagy generált adatkészletekért.
Általában ezek a hagyományos árképzési stratégiák, amelyeket a piacon követnek:
| Adattípus | Árazási stratégia |
|---|---|
| Ára egyetlen képfájlonként | |
| Ára másodpercenként, percenként, órában vagy egyedi képkockákon | |
| Ára másodpercenként, percenként vagy óránként | |
| Szavanként vagy mondatként áron |
De várj. Ez megint egy ökölszabály. Az adatkészletek beszerzésének tényleges költsége olyan tényezőktől is függ, mint:
- Az egyedi piaci szegmens, demográfiai vagy földrajzi terület, ahonnan az adatkészleteket be kell szerezni
- Az Ön használati esetének bonyolultsága
- Mennyi adatra van szüksége?
- Ideje piacra lépni
- Bármilyen személyre szabott követelmény és így tovább
Ha megfigyeli, tudni fogja, hogy az AI-projekthez szükséges képek tömeges beszerzésének költsége alacsonyabb lehet, de ha túl sok specifikációval rendelkezik, az árak megemelkedhetnek.
Az Ön beszerzési stratégiái
Ez trükkös. Mint láthatta, különböző módokon generálhat vagy forrásolhat adatokat az AI-modellekhez. A józan ész azt diktálja, hogy az ingyenes források a legjobbak, mivel komplikációk nélkül ingyenesen letöltheti a szükséges adatkészleteket.
Jelenleg az is úgy tűnik, hogy a fizetős források túl drágák. De ez az a hely, ahol a bonyodalom rétege hozzáadódik. Ha ingyenes erőforrásokból szerzi be az adatkészleteket, akkor több időt és energiát fordít az adatkészletek tisztítására, a vállalkozásspecifikus formátumba való összeállítására, majd egyenkénti megjegyzéseire. A folyamat során működési költségek merülnek fel.
Fizetős források esetén a fizetés egyszeri, és a gépre kész adatkészleteket is kézhez kapja a kívánt időpontban. A költséghatékonyság itt nagyon szubjektív. Ha úgy érzi, megengedheti magának, hogy időt szánjon ingyenes adatkészletek annotálására, akkor ennek megfelelő költségvetést készíthet. És ha úgy gondolja, hogy a verseny kiélezett, és korlátozott a piacra jutási ideje, hullámzási hatást kelthet a piacon, akkor előnyben kell részesítenie a fizetős forrásokat.
A költségvetés-tervezés lényege a konkrétumok lebontása és az egyes töredékek világos meghatározása. Ez a három tényező útitervként szolgálhat az AI képzési költségvetési folyamatához a jövőben.
Megtakarít a kiadásokon a házon belüli adatgyűjtéssel?
 A költségvetés tervezése során megvizsgáltuk, hogy a szabad források hogyan kényszerítik Önt hosszabb távon több kiadásra. Ekkor automatikusan elgondolkozott volna a házon belüli adatgyűjtési folyamat költséghatékonyságán.
A költségvetés tervezése során megvizsgáltuk, hogy a szabad források hogyan kényszerítik Önt hosszabb távon több kiadásra. Ekkor automatikusan elgondolkozott volna a házon belüli adatgyűjtési folyamat költséghatékonyságán.
Tudjuk, hogy még mindig tétovázik a fizetős forrásokkal kapcsolatban, és ezért ez a rész feloldja ezzel kapcsolatos szkepticizmusát, és rávilágít a házon belüli adatgenerálás rejtett költségeire.
Drága a házon belüli adatgyűjtés?
Igen, ez az!
Nos, itt egy részletes válasz. Költség minden, amit elkölt. Az ingyenes források megvitatása során kiderült, hogy pénzt, időt és erőfeszítést költ a folyamatra. Ez vonatkozik a házon belüli adatgyűjtésre is.
 Tekintettel arra, hogy vannak egyénileg meghatározott érintkezési pontjai vagy adatcsatornái, ez nem jelenti azt, hogy meg is lennének gépkész adatkészletek a végén. Az Ön által generált adatok továbbra is többnyire nyersek és strukturálatlanok lesznek. Előfordulhat, hogy az összes szükséges adatot egy helyen tárolja, de amit az adatok tartalmaznak, az mindenhol megtalálható.
Tekintettel arra, hogy vannak egyénileg meghatározott érintkezési pontjai vagy adatcsatornái, ez nem jelenti azt, hogy meg is lennének gépkész adatkészletek a végén. Az Ön által generált adatok továbbra is többnyire nyersek és strukturálatlanok lesznek. Előfordulhat, hogy az összes szükséges adatot egy helyen tárolja, de amit az adatok tartalmaznak, az mindenhol megtalálható.
Végső soron az alkalmazottak, adattudósok, annotátorok, minőségbiztosítási szakemberek és egyebek fizetésére kell költenie. Emellett költeni fog a jegyzetkészítő eszközök előfizetésére és
CMS, CRM és egyéb infrastrukturális költségek karbantartása.
Ezenkívül az adatkészleteknek vannak torzítási és pontossági aggályai, amelyeket manuálisan kell rendeznie. Ha pedig lemorzsolódási problémái vannak az AI képzési adatokkal foglalkozó csapatában, akkor új tagok toborzására, a folyamatokhoz való orientálására, az eszközei használatára való betanításra és egyebekre kell költenie.
Többet fog költeni, mint amennyit hosszú távon végül keresne. Vannak annotációs költségek is. Egy adott időpontban a házon belüli adatokkal végzett munka teljes költsége:
Felmerült költség = Annotátorok száma * Annotátoronkénti költség + Platform költsége
Ha a mesterséges intelligencia képzési naptárát hónapokra ütemezi, képzelje el, milyen költségekkel járna rendszeresen. Tehát ez az ideális megoldás az adatgyűjtési problémákra, vagy van más alternatíva?
Hogyan válasszuk ki a megfelelő AI-adatgyűjtő vállalatot
A mesterséges intelligencia adatgyűjtő cégének kiválasztása nem olyan bonyolult vagy időigényes, mint az ingyenes forrásokból történő adatgyűjtés. Csak néhány egyszerű tényezőt kell figyelembe vennie, majd kezet kell fognia az együttműködéshez.
Amikor elkezd adatszolgáltatót keresni, feltételezzük, hogy követte és figyelembe vette mindazt, amit eddig megbeszéltünk. Íme azonban egy gyors összefoglaló:
- Egy jól meghatározott használati esetet tart a szem előtt
- Az Ön piaci szegmense és adatigényei egyértelműen meghatározottak
- A költségvetés tervezése a helyén van
- És van elképzelése a szükséges adatok mennyiségéről
Ha ezeket az elemeket bejelöli, akkor megértjük, hogyan kereshet ideális képzési adatszolgáltatót.