
A mesterséges intelligencia és a nagy adatforgalom képes megoldást találni a globális problémákra, miközben előtérbe helyezi a helyi problémákat, és számos mélyreható módon átalakítja a világot. A mesterséges intelligencia mindenkinek kínál megoldásokat – és minden környezetben, az otthonoktól a munkahelyekig. AI számítógépekkel Gépi tanulás képzés, képes szimulálni az intelligens viselkedést és beszélgetéseket automatizáltan, de személyre szabottan.
Ennek ellenére a mesterséges intelligencia befogadási problémával néz szembe, és gyakran elfogult. Szerencsére összpontosítva mesterséges intelligencia etika újabb lehetőségeket nyithat meg a diverzifikáció és a befogadás terén azáltal, hogy a különféle képzési adatokon keresztül kiküszöböli a tudattalan torzítást.
A sokféleség jelentősége az AI képzési adatokban
 A képzési adatok sokfélesége és minősége összefügg, mivel az egyik hatással van a másikra, és befolyásolja az AI-megoldás kimenetelét. Az AI megoldás sikere attól függ változatos adatok arra van kiképezve. Az adatok sokfélesége megakadályozza a mesterséges intelligencia túlillesztését – ami azt jelenti, hogy a modell csak a betanításhoz használt adatokból teljesít vagy tanul azokból. Túlillesztés esetén az AI-modell nem tud eredményt adni, ha az edzés során nem használt adatokon tesztelik.
A képzési adatok sokfélesége és minősége összefügg, mivel az egyik hatással van a másikra, és befolyásolja az AI-megoldás kimenetelét. Az AI megoldás sikere attól függ változatos adatok arra van kiképezve. Az adatok sokfélesége megakadályozza a mesterséges intelligencia túlillesztését – ami azt jelenti, hogy a modell csak a betanításhoz használt adatokból teljesít vagy tanul azokból. Túlillesztés esetén az AI-modell nem tud eredményt adni, ha az edzés során nem használt adatokon tesztelik.
Az AI képzés jelenlegi állása dátum
Az adatok egyenlőtlensége vagy sokszínűségének hiánya tisztességtelen, etikátlan és nem inkluzív mesterségesintelligencia-megoldásokhoz vezetne, amelyek elmélyíthetik a diszkriminációt. De hogyan és miért kapcsolódik az adatok sokfélesége az AI-megoldásokhoz?
Az összes osztály egyenlőtlen ábrázolása az arcok téves azonosításához vezet – az egyik fontos eset a Google Fotók, amely a fekete párokat „gorilláknak” minősítette. A Meta pedig arra kéri a felhasználót, aki fekete férfiakról készült videót néz, hogy a felhasználó szeretné-e „továbbra is nézni a főemlősökről készült videókat”.
Például az etnikai vagy faji kisebbségek pontatlan vagy helytelen besorolása, különösen a chatbotokban, előítéletekhez vezethet az AI képzési rendszerekben. A 2019-es jelentés szerint Megkülönböztető rendszerek – nem, faj, hatalom az AI-ban, a mesterséges intelligenciát tanító tanárok több mint 80%-a férfi; A női AI-kutatók az FB-n mindössze 15%-ot és 10%-ot tesznek ki a Google-on.
A változatos képzési adatok hatása a mesterséges intelligencia teljesítményére
 Ha bizonyos csoportokat és közösségeket kihagyunk az adatábrázolásból, az algoritmusok torzulásához vezethet.
Ha bizonyos csoportokat és közösségeket kihagyunk az adatábrázolásból, az algoritmusok torzulásához vezethet.
Az adattorzítás gyakran véletlenül kerül be az adatrendszerekbe – bizonyos fajok vagy csoportok alulmintázásával. Amikor az arcfelismerő rendszereket különféle arcokra tanítják, ez segít a modellnek azonosítani a konkrét jellemzőket, például az arcszervek helyzetét és a színváltozatokat.
A címkék kiegyensúlyozatlan gyakoriságának másik eredménye az, hogy a rendszer a kisebbséget anomáliának tekintheti, ha nyomást gyakorol arra, hogy rövid időn belül kimenetet állítson elő.
Sokszínűség elérése a mesterséges intelligencia képzési adataiban
A másik oldalon egy változatos adatkészlet létrehozása is kihívást jelent. Az egyes osztályokra vonatkozó adatok puszta hiánya alulreprezentáltsághoz vezethet. Csökkenthető, ha az AI-fejlesztői csapatokat sokrétűbbé tesszük a képességek, az etnikai hovatartozás, a faj, a nem, a fegyelem és egyebek tekintetében. Ezen túlmenően a mesterséges intelligencia adatdiverzitási problémáinak megoldásának ideális módja az, ha a kezdetektől szembeszállunk velük, ahelyett, hogy megpróbálnánk kijavítani a történteket – a sokszínűséget az adatgyűjtés és a gondozás szakaszában is átitatjuk.
Az AI körüli felhajtástól függetlenül ez továbbra is az emberek által gyűjtött, kiválasztott és betanított adatoktól függ. Az emberek veleszületett elfogultsága tükröződik az általuk gyűjtött adatokban, és ez a tudattalan torzítás az ML modellekbe is beférkőzik.
Lépések a különféle edzési adatok gyűjtéséhez és összegyűjtéséhez
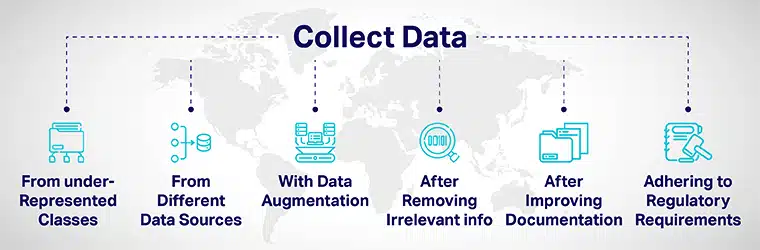
Adatok sokfélesége a következőkkel érhető el:
- Megfontoltan adjon hozzá több adatot az alulreprezentált osztályokból, és tegye ki modelljeit változatos adatpontoknak.
- Különböző adatforrásokból származó adatok gyűjtésével.
- Adatbővítéssel vagy az adatkészletek mesterséges manipulálásával az eredeti adatpontoktól egyértelműen eltérő új adatpontok növelése/befoglalása érdekében.
- Amikor jelentkezőket vesz fel a mesterséges intelligencia fejlesztési folyamatába, távolítson el minden, a munkával nem releváns információt a pályázatból.
- Az átláthatóság és az elszámoltathatóság javítása a modellek fejlesztésének és értékelésének dokumentálásának javításával.
- Szabályzatok bevezetése a sokszínűség építésére és inkluzivitás az AI-ban rendszerek alulról építkező szintről. Különböző kormányok iránymutatásokat dolgoztak ki a sokszínűség biztosítására és a mesterséges intelligencia torzításának csökkentésére, amely tisztességtelen eredményeket hozhat.
[Olvassa el még: További információ az AI képzési adatgyűjtési folyamatáról ]
Következtetés
Jelenleg csak néhány nagy technológiai vállalat és oktatási központ vesz részt kizárólagosan mesterséges intelligencia-megoldások fejlesztésében. Ezeket az elit tereket kirekesztés, diszkrimináció és elfogultság hatja át. Azonban ezek azok a területek, ahol a mesterséges intelligencia fejlesztése folyik, és a fejlett AI-rendszerek mögött meghúzódó logika tele van ugyanazzal az elfogultsággal, diszkriminációval és kirekesztéssel, amelyet az alulreprezentált csoportok viselnek.
A sokszínűség és a megkülönböztetésmentesség megvitatása során fontos megkérdőjelezni azokat az embereket, akiknek hasznára válik, és akiknek árt. Azt is meg kell vizsgálnunk, hogy kit hoz hátrányos helyzetbe – a „normális” ember eszméjének kikényszerítésével az MI potenciálisan „másokat” veszélyeztethet.
Az AI-adatok sokféleségének megvitatása a hatalmi viszonyok, a méltányosság és az igazságosság elismerése nélkül nem mutatja meg a nagyobb képet. Ahhoz, hogy teljes mértékben megértsük a mesterséges intelligencia képzési adatainak sokféleségét, és azt, hogy az emberek és a mesterséges intelligencia hogyan tudják együtt enyhíteni ezt a válságot, forduljon a Shaip mérnökeihez. Változatos mesterségesintelligencia-mérnökeink vannak, akik dinamikus és változatos adatokat tudnak szolgáltatni az Ön AI-megoldásaihoz.


