Ha Siri, Alexa, Cortana, Amazon Echo vagy másokat használ mindennapi élete részeként, akkor elfogadja, hogy Beszédfelismerés életünk mindenütt jelenlévő részévé vált. Ezek mesterséges intelligencia által hajtott A hangasszisztensek szöveggé alakítják a felhasználók verbális lekérdezéseit, értelmezik és megértik, amit a felhasználó mond, hogy megfelelő választ adjanak.
Minőségi adatgyűjtésre van szükség a megbízható beszéd-, felismerési modellek kialakításához. De fejlődni beszédfelismerő szoftver nem egyszerű feladat – éppen azért, mert az emberi beszédet a maga teljes bonyolultságában, például ritmusban, akcentusban, hangmagasságban és tisztaságban nehéz átírni. És ha érzelmeket ad hozzá ehhez az összetett keverékhez, az kihívássá válik.
Mi az a beszédfelismerés?
A beszédfelismerés a szoftver felismerő és feldolgozó képessége emberi beszéd szövegbe. Bár a hangfelismerés és a beszédfelismerés közötti különbség sokak számára szubjektívnek tűnhet, van néhány alapvető különbség a kettő között.
Bár a beszéd- és hangfelismerés is a hangasszisztens technológia részét képezi, két különböző funkciót lát el. A beszédfelismerés automatikusan átírja az emberi beszédet és a parancsokat szöveggé, míg a hangfelismerés csak a beszélő hangjának felismerésével foglalkozik.
A beszédfelismerés típusai
Mielőtt belevágnánk beszédfelismerési típusok, vessünk egy rövid pillantást a beszédfelismerési adatokra.
A beszédfelismerési adatok emberi beszédhangfelvételek és szöveges átírások gyűjteménye, amelyek segítenek a gépi tanulási rendszerek képzésében hangfelismerés.
A hangfelvételek és átiratok bekerülnek az ML rendszerbe, így az algoritmus betanítható a beszéd árnyalatainak felismerésére és jelentésének megértésére.
Bár sok helyen ingyenes előre csomagolt adatkészleteket kaphat, a legjobb, ha beszerez testreszabott adatkészletek projektjeihez. Egyéni adatkészlettel kiválaszthatja a gyűjtemény méretét, a hang- és hangszórókövetelményeket, valamint a nyelvet.
Beszédadat-spektrum
Beszédadatok spektrum azonosítja a beszéd minőségét és hangmagasságát a természetestől a természetellenesig.
Szkriptelt beszédfelismerési adatok
Ahogy a neve is sugallja, a szkriptelt beszéd az adatok ellenőrzött formája. A beszélők meghatározott kifejezéseket rögzítenek egy előkészített szövegből. Ezeket jellemzően parancsok kézbesítésére használják, hangsúlyozva, hogy a szó vagy kifejezés inkább mondják, mint azt, amit mondanak.
A szkriptelt beszédfelismerés használható olyan hangasszisztens fejlesztésekor, amely felveszi a különféle hangszórók ékezeteivel kiadott parancsokat.
Forgatókönyv-alapú beszédfelismerés
Egy forgatókönyv-alapú beszédben a beszélőt arra kérik, hogy képzeljen el egy adott forgatókönyvet, és adja ki a hangutasítás forgatókönyv alapján. Ily módon az eredmény olyan hangparancsok gyűjteménye, amelyek nem szkriptek, hanem vezéreltek.
Forgatókönyv-alapú beszédadatokra van szükség azoknak a fejlesztőknek, akik olyan eszközt szeretnének kifejleszteni, amely megérti a mindennapi beszédet annak különféle árnyalataival együtt. Például útbaigazítást kér, hogy eljusson a legközelebbi Pizza Huthoz, különféle kérdések segítségével.
Természetes beszédfelismerés
A beszédspektrum végén a spontán, természetes és semmilyen módon nem kontrollált beszéd található. A beszélő szabadon beszél a természetes társalgási hangnemével, nyelvével, hangmagasságával és tenorjával.
Ha több hangszórós beszédfelismerésre szeretne ML alapú alkalmazást betanítani, akkor egy szkript nélküli ill társalgási beszéd adatkészlet hasznos.
Adatgyűjtési összetevők beszédprojektekhez
 A beszédadatok gyűjtésének számos lépése biztosítja, hogy az összegyűjtött adatok minőségiek legyenek, és segítik a kiváló minőségű AI-alapú modellek képzését.
A beszédadatok gyűjtésének számos lépése biztosítja, hogy az összegyűjtött adatok minőségiek legyenek, és segítik a kiváló minőségű AI-alapú modellek képzését.
A szükséges felhasználói válaszok megértése
Kezdje azzal, hogy megértse a modellhez szükséges felhasználói válaszokat. A beszédfelismerő modell kidolgozásához olyan adatokat kell gyűjtenie, amelyek pontosan reprezentálják a szükséges tartalmat. Gyűjtsön adatokat a valós interakciókból, hogy megértse a felhasználói interakciókat és válaszokat. Ha mesterséges intelligencia-alapú csevegési asszisztenst épít, nézze meg a csevegési naplókat, a hívásfelvételeket és a csevegési párbeszédpanel válaszait egy adatkészlet létrehozásához.
Vizsgálja meg a tartományspecifikus nyelvet
A beszédfelismerési adatkészlethez általános és tartományspecifikus tartalom is szükséges. Miután összegyűjtötte az általános beszédadatokat, át kell szűrnie az adatokat, és el kell választania az általánost a konkréttól.
Például az ügyfelek telefonálhatnak, és időpontot kérhetnek a glaukóma ellenőrzésére egy szemészeti központban. Az időpontkérés nagyon általános kifejezés, de a glaukóma tartomány-specifikus.
Ezenkívül a beszédfelismerő ML-modell betanításakor ügyeljen arra, hogy a kifejezések azonosítására tanítsa, nem pedig egyenként felismert szavakat.
Emberi beszéd rögzítése
Az előző két lépésből származó adatok összegyűjtése után a következő lépésben rávennénk az embereket az összegyűjtött állítások rögzítésére.
Elengedhetetlen a szkript ideális hosszának megőrzése. Ha arra kérik az embereket, hogy olvassanak el több mint 15 percnyi szöveget, az kontraproduktív lehet. Tartson legalább 2-3 másodperces szünetet az egyes rögzített kijelentések között.
Hagyja, hogy a felvétel dinamikus legyen
Készítsen beszédtárat különféle emberekről, beszédhangsúlyokról, stílusokról, amelyeket különböző körülmények között, eszközökön és környezetekben rögzítettek. Ha a jövőbeni felhasználók többsége a vezetékes vonalat fogja használni, a beszédgyűjtő adatbázisnak jelentős reprezentációval kell rendelkeznie, amely megfelel ennek a követelménynek.

Indukáljon változékonyságot a beszédrögzítésben
A célkörnyezet beállítása után kérje meg az adatgyűjtés alanyait, hogy olvassák el az elkészített szkriptet hasonló környezetben. Kérd meg az alanyokat, hogy ne aggódjanak a hibák miatt, és tartsák meg a lehető legtermészetesebben az előadásmódot. Az ötlet az, hogy egy nagy csoport ember rögzítse a forgatókönyvet ugyanabban a környezetben.
A beszédek átírása
Miután felvette a forgatókönyvet több tárgyból (hibásan), folytassa az átírással. Tartsa érintetlenül a hibákat, mert ez segít az összegyűjtött adatok dinamizmusának és változatosságának elérésében.
Ahelyett, hogy az emberek szóról szóra átírnák a teljes szöveget, használhat egy beszéd-szöveggé motort az átíráshoz. Javasoljuk azonban, hogy a hibák kijavításához alkalmazzon emberi átírókat.
Készítsen tesztkészletet
A tesztkészlet kidolgozása kulcsfontosságú, mivel az éllovas a nyelvi modell.
Készítsen párost a beszédből és a megfelelő szövegből, és bontsa őket szegmensekre.
Az összegyűjtött elemek összegyűjtése után vegyünk ki egy 20%-os mintát, amelyből a tesztkészlet alakul ki. Ez nem a betanítási készlet, de ezek a kivont adatok tájékoztatják Önt, ha a betanított modell olyan hangot ír át, amelyre nem tanították.
Nyelvi képzési modell felépítése és mérése
Most készítse el a beszédfelismerő nyelvi modellt a tartományspecifikus utasítások és szükség esetén további variációk felhasználásával. Miután betanította a modellt, el kell kezdenie a mérést.
Vegye ki a képzési modellt (80%-ban kiválasztott hangszegmenssel), és tesztelje a tesztkészlettel (kivont 20%-os adatkészlettel), hogy ellenőrizze az előrejelzéseket és a megbízhatóságot. Ellenőrizze a hibákat, mintákat, és összpontosítson a javítható környezeti tényezőkre.
Lehetséges használati esetek vagy alkalmazások
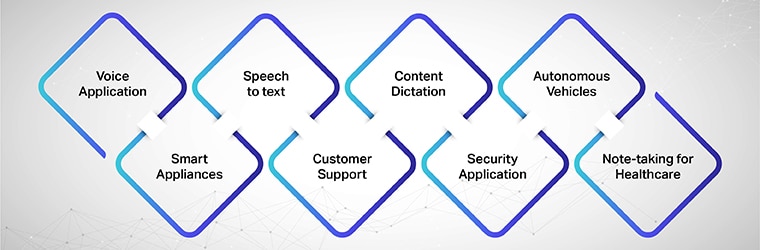
Hangalkalmazás, Intelligens készülékek, Beszéd szöveggé, Ügyfélszolgálat, Tartalmi diktálás, Biztonsági alkalmazás, Autonóm járművek, Jegyzetkészítés az egészségügyben.
A beszédfelismerés a lehetőségek világát nyitja meg, és a hangalkalmazások felhasználói alkalmazása az évek során egyre nőtt.
Néhány gyakori alkalmazása beszédfelismerő technológia következők:
Hangalapú keresési alkalmazás
A Google szerint körülbelül 20% a Google alkalmazásban végzett keresések közül hangalapú. Nyolc milliárd ember az előrejelzések szerint 2023-ra hangasszisztenseket fognak használni, ami meredek növekedés a 6.4-re előre jelzett 2022 milliárdhoz képest.
A hangalapú keresés alkalmazása az évek során jelentősen megnövekedett, és ez a tendencia az előrejelzések szerint folytatódni fog. A fogyasztók a hangalapú keresésre hagyatkoznak a lekérdezések kereséséhez, a termékek vásárlásához, a vállalkozások helyének meghatározásához, a helyi vállalkozások megtalálásához stb.
Otthoni eszközök/okos készülékek
A hangfelismerő technológiát arra használják, hogy hangutasításokat adjanak otthoni okoseszközökhöz, például tévékhez, lámpákhoz és egyéb készülékekhez. A fogyasztók 66% -a az Egyesült Királyságban, az Egyesült Államokban és Németországban kijelentették, hogy hangasszisztenseket használtak okoseszközök és hangszórók használatakor.
Beszéd a szöveghez
A beszéd-szöveg alkalmazásokat arra használják, hogy segítsék a szabad számítástechnikát e-mailek, dokumentumok, jelentések és egyebek beírásakor. Beszéd a szöveghez kiküszöböli a dokumentumok gépelésének, a könyvek és levelek írásának, a videók feliratozásának és a szöveg fordításának idejét.
Vevőszolgálat
A beszédfelismerő alkalmazásokat elsősorban az ügyfélszolgálatban és a támogatásban használják. A beszédfelismerő rendszer segíti az ügyfélszolgálati megoldásokat a hét minden napján, 24 órában elérhető áron, korlátozott számú képviselővel.
Tartalmi diktálás
A tartalmi diktálás egy másik dolog beszédfelismerési használati eset amely segít a hallgatóknak és az oktatóknak átfogó tartalmat írni az idő töredéke alatt. Nagyon hasznos a vakság vagy látásproblémák miatt hátrányos helyzetű tanulók számára.
Biztonsági alkalmazás
A hangfelismerést széles körben használják biztonsági és hitelesítési célokra, egyedi hangjellemzők azonosításával. Ahelyett, hogy az érintett személy személyes adatai alapján azonosítaná magát, a hangbiometrikus adatok növelik a biztonságot.
Ezenkívül a biztonsági célú hangfelismerés javította az ügyfelek elégedettségét, mivel megszünteti a kiterjesztett bejelentkezési folyamatot és a hitelesítő adatok megkettőzését.
Hangutasítások járművekhez
A járművek, elsősorban az autók, már rendelkeznek közös hangfelismerő funkcióval a vezetési biztonság fokozása érdekében. Segíti a vezetőt a vezetésre összpontosítani azáltal, hogy olyan egyszerű hangutasításokat fogad el, mint a rádióállomások kiválasztása, hívások kezdeményezése vagy a hangerő csökkentése.
Jegyzetírás az egészségügyért
A beszédfelismerő algoritmusokkal épített orvosi átíró szoftver könnyedén rögzíti az orvosok hangjegyzeteit, parancsait, diagnózisait és tüneteit. Az orvosi jegyzetírás növeli az egészségügyi ágazat minőségét és sürgősségét.
Van olyan beszédfelismerő projekt a fejében, amely átalakíthatja vállalkozását? Csak egy testreszabott beszédfelismerő adatkészletre lehet szüksége.
A mesterséges intelligencia alapú beszédfelismerő szoftvert megbízható adatkészletekre kell képezni a gépi tanulási algoritmusokon, hogy integrálja a szintaxist, a nyelvtant, a mondatszerkezetet, az érzelmeket és az emberi beszéd árnyalatait. A legfontosabb, hogy a szoftvernek folyamatosan tanulnia kell és reagálnia kell – minden interakcióval növekszik.
A Shaipnél teljesen testreszabott beszédfelismerési adatkészleteket biztosítunk különféle gépi tanulási projektekhez. A Shaip segítségével hozzáférhet a legjobb minőségű, személyre szabott edzési adatok amelyek segítségével megbízható beszédfelismerő rendszert lehet felépíteni és forgalmazni. Lépjen kapcsolatba szakértőinkkel kínálatunk átfogó megismeréséhez.
[Olvassa el még: A társalgási AI teljes útmutatója]