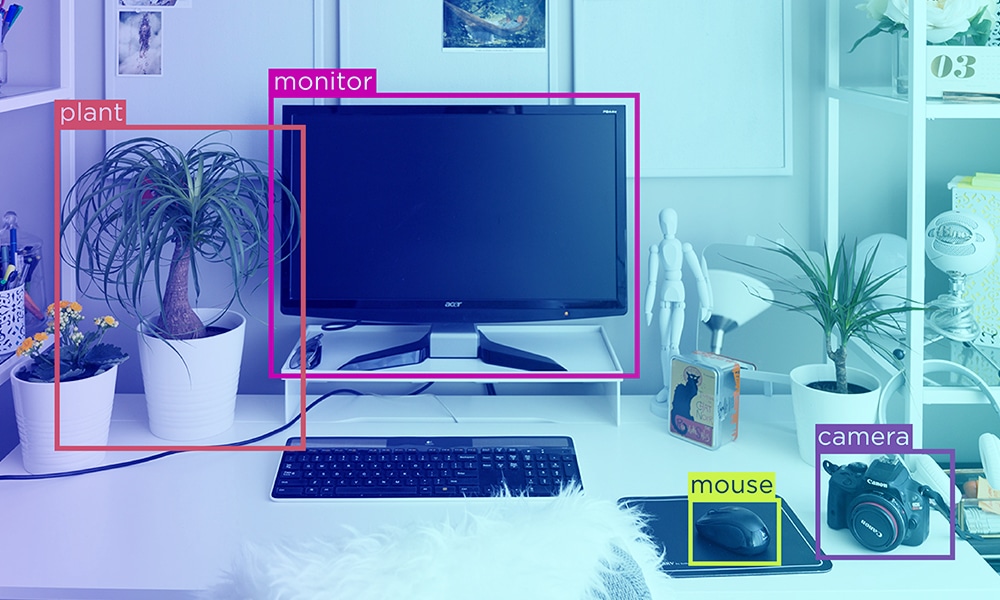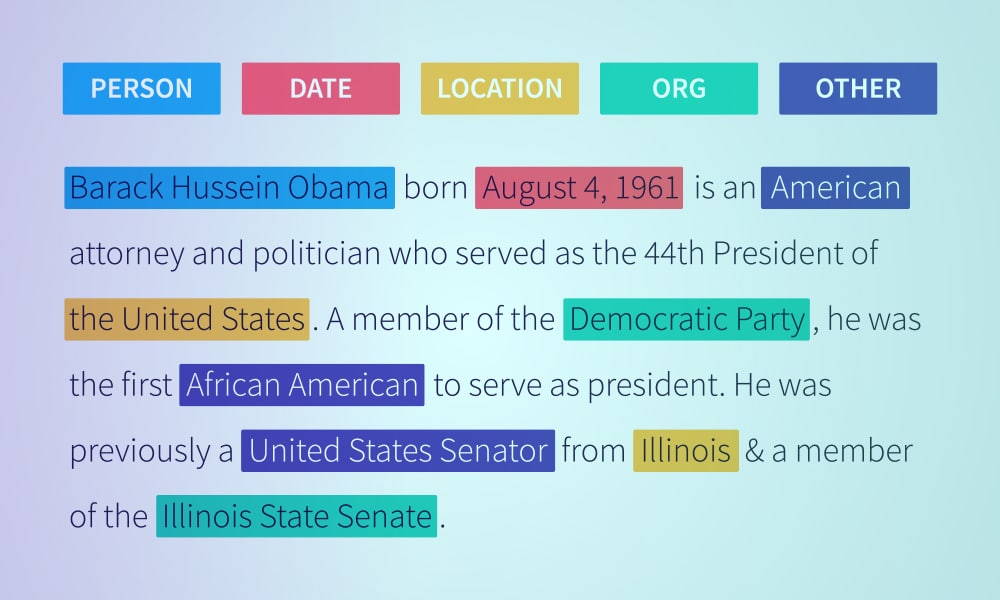
Az adatok az a szuperhatalom, amely átalakítja a digitális tájat a mai világban. Az e-mailektől a közösségi média bejegyzésekig mindenhol vannak adatok. Igaz, hogy a vállalkozások soha nem fértek hozzá ennyi adathoz, de vajon elegendő-e az adatokhoz való hozzáférés? A gazdag információforrás használhatatlanná vagy elavulttá válik, ha nem dolgozzák fel.
A strukturálatlan szöveg gazdag információforrás lehet, de csak akkor lesz hasznos a vállalkozások számára, ha az adatokat rendszerezzük, kategorizáljuk és elemezzük. A strukturálatlan adatok, például szöveg, hang, videók és közösségi média összege 80 -90% az összes adatból. Ráadásul a hírek szerint a szervezetek alig 18%-a használja ki szervezete strukturálatlan adatait.
A szervereken tárolt terabájtnyi adatok kézi átvizsgálása időigényes és őszintén szólva lehetetlen feladat. A gépi tanulás, a természetes nyelvi feldolgozás és az automatizálás fejlődésével azonban lehetőség nyílik a szöveges adatok gyors és hatékony strukturálására és elemzésére. Az adatelemzés első lépése az szöveges besorolás.
Mi az a szövegosztályozás?
A szöveg osztályozása vagy kategorizálása a szöveg előre meghatározott kategóriákba vagy osztályokba történő csoportosításának folyamata. Ezzel a gépi tanulási megközelítéssel bármely szöveg – dokumentumok, webfájlok, tanulmányok, jogi dokumentumok, orvosi jelentések stb – osztályozható, rendszerezhető és strukturálható.
A szövegbesorolás a természetes nyelvi feldolgozás alapvető lépése, amely többféleképpen is használható a levélszemét-észlelésben. Érzelemelemzés, szándékfelismerés, adatcímkézés és még sok más.
A szöveges osztályozás lehetséges használati esetei
 A gépi tanulási szövegosztályozás használatának számos előnye van, mint például a méretezhetőség, az elemzés sebessége, a konzisztencia és a valós idejű beszélgetések alapján történő gyors döntések lehetősége.
A gépi tanulási szövegosztályozás használatának számos előnye van, mint például a méretezhetőség, az elemzés sebessége, a konzisztencia és a valós idejű beszélgetések alapján történő gyors döntések lehetősége.
Ha az ML-modell olyan mesterséges intelligencia használatára van kiképezve, amely automatikusan előre beállított kategóriákba sorolja az elemeket, akkor az alkalmi böngészőket gyorsan ügyfelekké alakíthatja.
Szövegosztályozási folyamat
A szövegosztályozási folyamat az adatok előfeldolgozásával, jellemző kiválasztásával, kinyerésével és osztályozásával kezdődik.

Előfeldolgozás
Tokenizálás: A szöveget kisebb és egyszerűbb szövegformákra bontja az egyszerű osztályozás érdekében.
Normalizálás: A dokumentumban lévő összes szövegnek azonos szintűnek kell lennie. A normalizálás néhány formája:
- Nyelvtani vagy szerkezeti szabványok fenntartása a szövegben, például a szóközök vagy írásjelek eltávolítása. Vagy kisbetűk megtartása az egész szövegben.
- Előtagok és utótagok eltávolítása a szavakból, és visszahelyezése az alapszavakhoz.
- Az olyan stopszavak eltávolítása, mint például az „és”, „az” „a” és egyebek, amelyek nem adnak hozzáadott értéket a szöveghez.
Funkció kiválasztása
A funkciók kiválasztása a szövegosztályozás alapvető lépése. A folyamat célja a szövegek legrelevánsabb jellemzőkkel való megjelenítése. A funkciók kiválasztása segít eltávolítani a nem releváns adatokat, és javítja a pontosságot.
A funkció kiválasztása csökkenti a bemeneti változót a modellben azáltal, hogy csak a legrelevánsabb adatokat használja és kiküszöböli a zajt. Az Ön által keresett megoldás típusa alapján az AI modelljeit úgy lehet megtervezni, hogy csak a releváns jellemzőket válasszák ki a szövegből.
Funkciókivonás
A funkciók kinyerése egy opcionális lépés, amelyet egyes vállalkozások vállalnak további kulcsfontosságú funkciók kinyerésére az adatokból. A jellemzők kinyerése számos technikát használ, például leképezést, szűrést és klaszterezést. A jellemzők kinyerésének elsődleges előnye – segít eltávolítani a redundáns adatokat, és javítja az ML-modell fejlesztési sebességét.
Adatok címkézése előre meghatározott kategóriákhoz
A szöveg előre meghatározott kategóriákhoz való címkézése a szövegosztályozás utolsó lépése. Ezt háromféleképpen lehet megtenni,
- Kézi címkézés
- Szabályalapú egyeztetés
- Tanulási algoritmusok – A tanulóalgoritmusok további két kategóriába sorolhatók, például felügyelt címkézés és nem felügyelt címkézés.
- Felügyelt tanulás: Az ML-modell automatikusan igazítja a címkéket a felügyelt címkézésben lévő, kategorizált adatokhoz. Ha már rendelkezésre állnak a kategorizált adatok, az ML algoritmusok leképezhetik a függvényt a címkék és a szöveg között.
- Felügyelet nélküli tanulás: Ez akkor fordul elő, ha hiányzik a korábban meglévő címkézett adat. Az ML modellek klaszterezést és szabályalapú algoritmusokat használnak a hasonló szövegek csoportosítására, például termékvásárlási előzmények, vélemények, személyes adatok és jegyek alapján. Ezek a széles csoportok tovább elemezhetők, hogy értékes ügyfél-specifikus betekintést nyerhessenek, amelyek felhasználhatók személyre szabott ügyfélmegközelítések megtervezéséhez.
A szöveges osztályozásnak többféle felhasználási módja létezik az egyes iparágakban. Bár a szöveges adatokból értékes ismeretek összegyűjtését, csoportosítását, osztályozását és kinyerését mindig is több területen használták, a szöveges osztályozás a marketingben, a termékfejlesztésben, az ügyfélszolgálatban, a menedzsmentben és az adminisztrációban keresi a lehetőségeit. Segíti a vállalkozásokat versenyképes intelligencia, piaci és vásárlói ismeretek megszerzésében, valamint adatalapú üzleti döntések meghozatalában.
Hatékony és áttekinthető szövegosztályozó eszközt kifejleszteni nem könnyű. Ennek ellenére a Shaip adatpartnerével hatékony, méretezhető és költséghatékony AI-alapú szövegosztályozó eszközt fejleszthet ki. Rengetegünk van pontosan megjelölt és használatra kész adatkészletek amelyek testreszabhatók a modell egyedi követelményei szerint. Versenyelőnnyé alakítjuk szövegét; lépjen kapcsolatba még ma.